\n
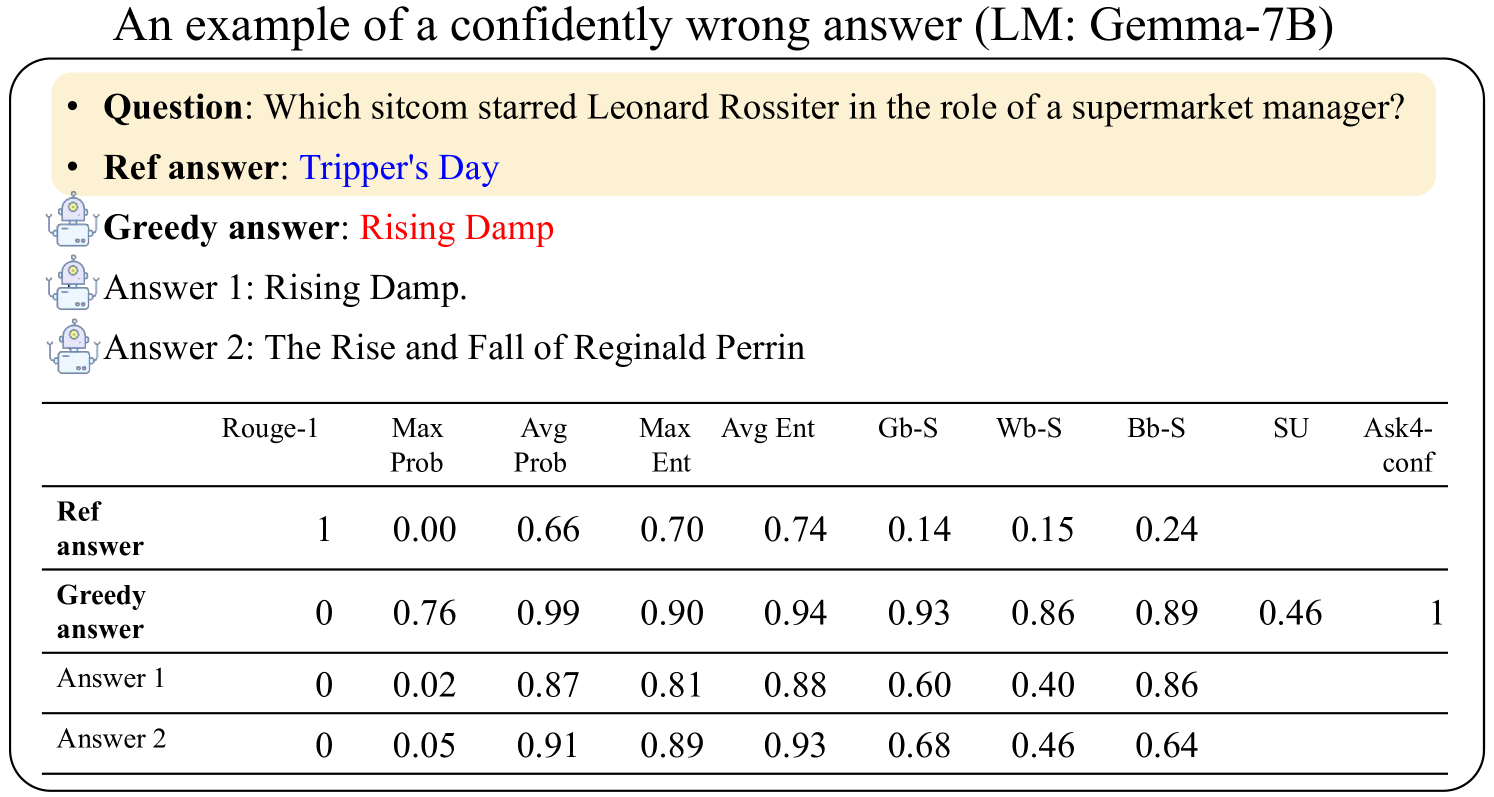
## Data Table: Confidently Wrong Answer Evaluation (LM: Gemma-7B)
### Overview
This image presents a data table evaluating the performance of a Large Language Model (LM), specifically Gemma-7B, on a question-answering task. The table compares the model's "Greedy answer" and alternative answers ("Answer 1", "Answer 2") against a "Ref answer" (reference answer). The evaluation is based on several metrics: Rouge-1, Max Prob, Avg Prob, Max Ent, Avg Ent, Gb-S, Wb-S, Bb-S, SU, and Ask4-conf. The question being answered is: "Which sitcom starred Leonard Rossiter in the role of a supermarket manager?".
### Components/Axes
* **Rows:** Represent different answer types: "Ref answer", "Greedy answer", "Answer 1", "Answer 2".
* **Columns:** Represent evaluation metrics:
* Rouge-1
* Max Prob
* Avg Prob
* Max Ent
* Avg Ent
* Gb-S
* Wb-S
* Bb-S
* SU
* Ask4-conf
* **Header Text:** "An example of a confidently wrong answer (LM: Gemma-7B)"
* **Question:** "Which sitcom starred Leonard Rossiter in the role of a supermarket manager?"
* **Ref answer:** "Tripper's Day"
* **Greedy answer:** "Rising Damp"
* **Answer 1:** "Rising Damp."
* **Answer 2:** "The Rise and Fall of Reginald Perrin"
### Detailed Analysis or Content Details
The table contains numerical values for each metric and answer type. Here's a breakdown:
| Answer Type | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
|---------------|---------|----------|----------|---------|---------|------|------|------|------|-----------|
| Ref answer | 1 | 0.00 | 0.66 | 0.70 | 0.74 | 0.14 | 0.15 | 0.24 | | |
| Greedy answer | 0 | 0.76 | 0.99 | 0.90 | 0.94 | 0.93 | 0.86 | 0.89 | 0.46 | 1 |
| Answer 1 | 0 | 0.02 | 0.87 | 0.81 | 0.88 | 0.60 | 0.40 | 0.86 | | |
| Answer 2 | 0 | 0.05 | 0.91 | 0.89 | 0.93 | 0.68 | 0.46 | 0.64 | | |
**Trends and Observations:**
* **Rouge-1:** The "Ref answer" has a Rouge-1 score of 1, while all other answers have a score of 0.
* **Max Prob:** The "Greedy answer" has the highest Max Prob score (0.76), significantly higher than "Answer 1" (0.02) and "Answer 2" (0.05).
* **Avg Prob:** The "Greedy answer" has a very high Avg Prob score (0.99), indicating high average probability across the answer. "Answer 1" and "Answer 2" also have high Avg Prob scores (0.87 and 0.91 respectively).
* **Max Ent & Avg Ent:** The "Greedy answer" also shows high Max Ent (0.90) and Avg Ent (0.94) scores.
* **Gb-S, Wb-S, Bb-S:** The "Greedy answer" consistently scores high on these metrics (0.93, 0.86, 0.89), while "Answer 1" and "Answer 2" have lower scores.
* **SU:** The "Greedy answer" has a SU score of 0.46.
* **Ask4-conf:** The "Greedy answer" has a perfect confidence score of 1.
### Key Observations
The model (Gemma-7B) provides a "Greedy answer" ("Rising Damp") with high confidence (Ask4-conf = 1) and high probabilities (Max Prob, Avg Prob). However, this answer is incorrect, as the "Ref answer" is "Tripper's Day". The Rouge-1 score of 0 for the "Greedy answer" confirms it is not a match for the reference answer. This demonstrates a case where the model is confidently wrong.
### Interpretation
This data illustrates a critical issue in Large Language Models: high confidence does not necessarily equate to correctness. The model is highly certain about an incorrect answer, as evidenced by the high probability scores and the perfect Ask4-conf score. This highlights the importance of evaluating LLMs not just on their confidence, but also on the factual accuracy of their responses. The high scores for "Answer 1" and "Answer 2" on Avg Prob suggest they are plausible answers, but still incorrect. The Rouge-1 score being 0 for all answers except the reference answer confirms that the model is struggling with this specific question. This example serves as a cautionary tale about relying solely on LLM outputs without verification.