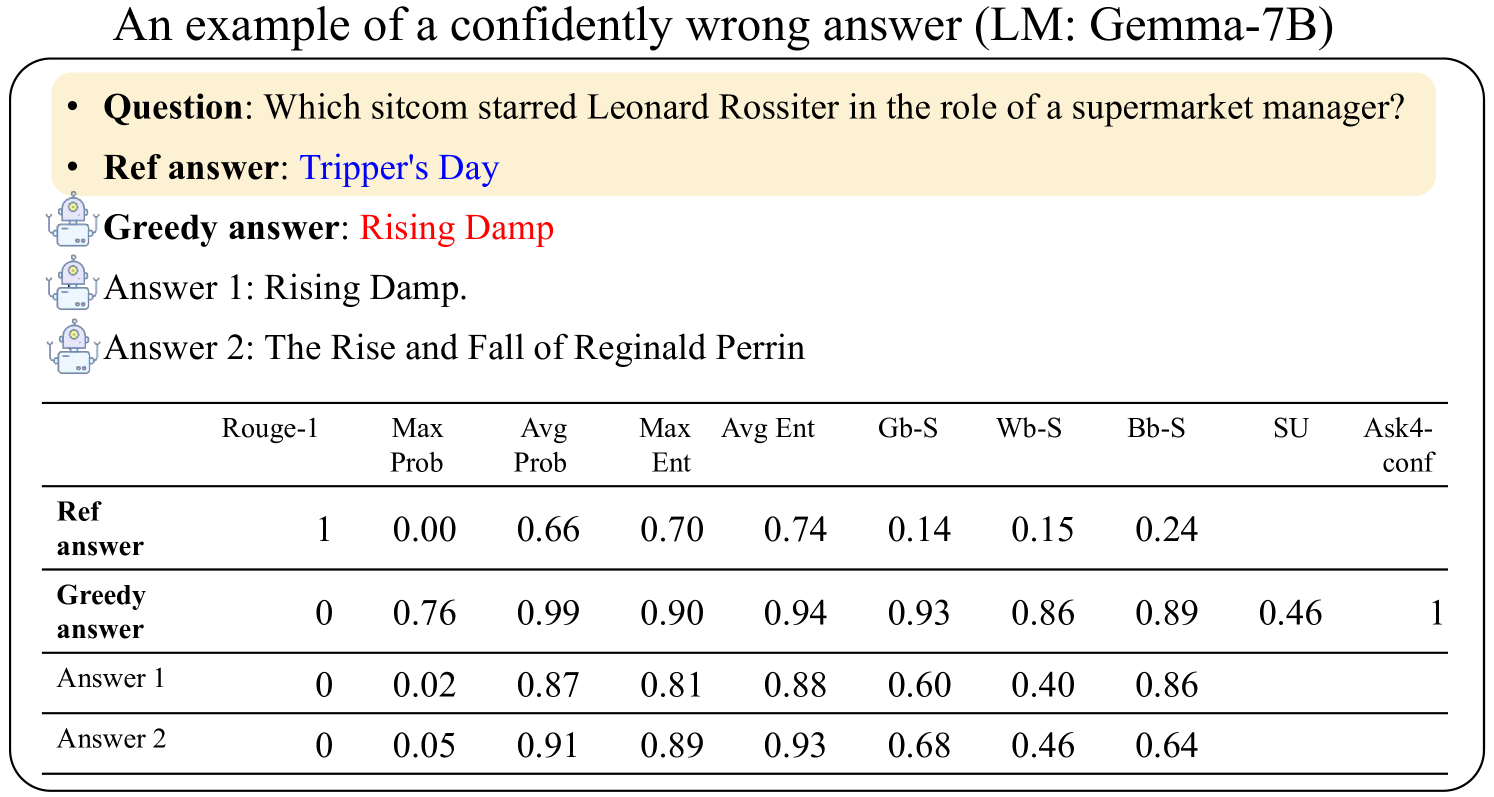
## Screenshot: Confidently Wrong Answer Example (LM: Gemma-7B)
### Overview
The image shows a question-answering scenario with statistical metrics comparing different responses. The question asks which sitcom starred Leonard Rossiter as a supermarket manager. The reference answer is "Tripper's Day," while a "greedy answer" ("Rising Damp") is highlighted in red. Two additional answers are provided, along with a table of metrics (Rouge-1, Max Prob, Avg Prob, etc.) for each response.
### Components/Axes
- **Textual Elements**:
- **Question**: "Which sitcom starred Leonard Rossiter in the role of a supermarket manager?"
- **Reference Answer**: "Tripper's Day" (highlighted in blue).
- **Greedy Answer**: "Rising Damp" (highlighted in red).
- **Answer 1**: "Rising Damp."
- **Answer 2**: "The Rise and Fall of Reginald Perrin."
- **Table Structure**:
- **Columns**:
- Rouge-1
- Max Prob
- Avg Prob
- Max Ent
- Avg Ent
- Gb-S
- Wb-S
- Bb-S
- SU
- Ask4-conf
- **Rows**:
- Ref answer
- Greedy answer
- Answer 1
- Answer 2
### Detailed Analysis
#### Table Data
| Component | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
|------------------|---------|----------|----------|---------|---------|------|------|------|----|-----------|
| **Ref answer** | 1.00 | 0.00 | 0.66 | 0.70 | 0.74 | 0.14 | 0.15 | 0.24 | - | - |
| **Greedy answer**| 0.00 | 0.76 | 0.99 | 0.90 | 0.94 | 0.93 | 0.86 | 0.89 | 0.46 | 1 |
| **Answer 1** | 0.00 | 0.02 | 0.87 | 0.81 | 0.88 | 0.60 | 0.40 | 0.86 | - | - |
| **Answer 2** | 0.00 | 0.05 | 0.91 | 0.89 | 0.93 | 0.68 | 0.46 | 0.64 | - | - |
#### Key Observations
1. **Reference Answer ("Tripper's Day")**:
- Perfect Rouge-1 (1.00) but Max Prob = 0.00, indicating the model assigned zero confidence to the correct answer.
- Low Gb-S (0.14) and Wb-S (0.15) suggest poor alignment with ground-truth and word-based similarity.
2. **Greedy Answer ("Rising Damp")**:
- Rouge-1 = 0.00 (completely incorrect) but Max Prob = 0.76 (high confidence).
- High Avg Prob (0.99) and Avg Ent (0.94) indicate the model was overly confident in this incorrect response.
- Ask4-conf = 1 (100% confidence) despite being wrong.
3. **Answer 1 ("Rising Damp")**:
- Same as the greedy answer but with lower Max Prob (0.02) and Avg Prob (0.87).
- Moderate Gb-S (0.60) and Wb-S (0.40) suggest partial alignment with ground-truth.
4. **Answer 2 ("The Rise and Fall of Reginald Perrin")**:
- Rouge-1 = 0.00 (incorrect) but higher Max Prob (0.05) and Avg Prob (0.91) than Answer 1.
- Slightly better Gb-S (0.68) and Wb-S (0.46) than Answer 1.
### Interpretation
- **Model Behavior**:
- The model exhibits **overconfidence** in incorrect answers (e.g., "Rising Damp" with 76% Max Prob but 0 Rouge-1).
- The reference answer ("Tripper's Day") is correct but assigned zero confidence, highlighting a **failure to recognize the correct response**.
- The greedy answer's high confidence (Ask4-conf = 1) despite being wrong suggests a **bias toward high-probability outputs**, even when they are factually incorrect.
- **Metrics Correlation**:
- Rouge-1 (exact match) and Max Prob (model confidence) are inversely related for the reference answer (1.00 vs. 0.00).
- Greedy answer's high Avg Prob (0.99) and low Rouge-1 (0.00) indicate a **disconnect between model confidence and factual accuracy**.
- **Anomalies**:
- The reference answer's Max Prob = 0.00 is unusual, as correct answers typically receive higher confidence.
- Answer 2's higher Avg Prob (0.91) than Answer 1 (0.87) despite both being incorrect suggests the model prioritizes **lexical similarity** over factual correctness.
This data underscores the challenge of balancing **confidence calibration** and **factual accuracy** in language models, particularly when dealing with ambiguous or misleading questions.