\n
## Heatmap: Layer Activation vs. Token Position
### Overview
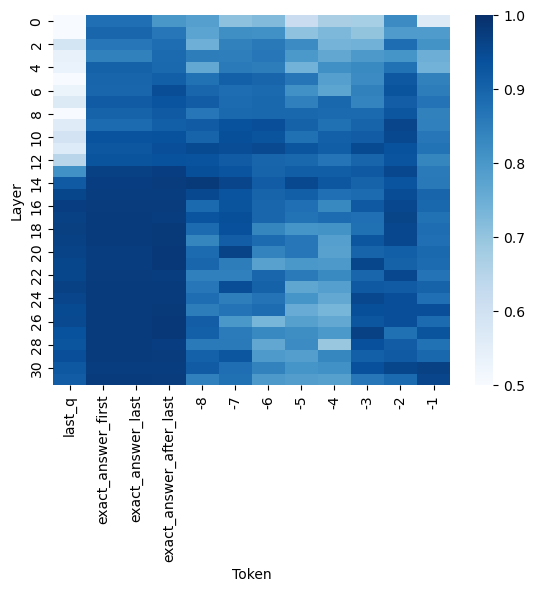
The image presents a heatmap visualizing the relationship between neural network layers and token positions. The color intensity represents a numerical value, likely indicating activation strength or attention weight. The heatmap spans 32 layers (numbered 2 to 30) against 9 token positions (labeled 'last_q', 'exact_answer_first', 'exact_answer_last', 'exact_answer_after_last', and tokens -8 to -1). A colorbar on the right indicates the value scale from 0.5 to 1.0.
### Components/Axes
* **X-axis (Horizontal):** "Token" - Represents the position of a token in a sequence. The tokens are labeled as follows: 'last_q', 'exact_answer_first', 'exact_answer_last', 'exact_answer_after_last', '-8', '-7', '-6', '-5', '-4', '-3', '-2', '-1'.
* **Y-axis (Vertical):** "Layer" - Represents the layer number in a neural network, ranging from 2 to 30.
* **Colorbar:** Located on the right side of the heatmap. The scale ranges from 0.5 (lightest color) to 1.0 (darkest color).
* **Data:** The heatmap itself, with each cell representing the value corresponding to a specific layer and token position.
### Detailed Analysis
The heatmap shows varying levels of activation across layers and tokens. The color intensity is used to represent the value.
Here's a breakdown of approximate values, reading from the heatmap:
* **'last_q' Token:**
* Layer 2: ~0.95
* Layer 4: ~0.95
* Layer 6: ~0.9
* Layer 8: ~0.85
* Layer 10: ~0.8
* Layer 12: ~0.75
* Layer 14: ~0.7
* Layer 16: ~0.68
* Layer 18: ~0.65
* Layer 20: ~0.6
* Layer 22: ~0.6
* Layer 24: ~0.65
* Layer 26: ~0.7
* Layer 28: ~0.75
* Layer 30: ~0.8
* **'exact_answer_first' Token:**
* Layer 2: ~0.9
* Layer 4: ~0.9
* Layer 6: ~0.85
* Layer 8: ~0.8
* Layer 10: ~0.75
* Layer 12: ~0.7
* Layer 14: ~0.65
* Layer 16: ~0.6
* Layer 18: ~0.58
* Layer 20: ~0.58
* Layer 22: ~0.6
* Layer 24: ~0.65
* Layer 26: ~0.7
* Layer 28: ~0.75
* Layer 30: ~0.8
* **'exact_answer_last' Token:**
* Layer 2: ~0.9
* Layer 4: ~0.9
* Layer 6: ~0.85
* Layer 8: ~0.8
* Layer 10: ~0.75
* Layer 12: ~0.7
* Layer 14: ~0.65
* Layer 16: ~0.6
* Layer 18: ~0.58
* Layer 20: ~0.58
* Layer 22: ~0.6
* Layer 24: ~0.65
* Layer 26: ~0.7
* Layer 28: ~0.75
* Layer 30: ~0.8
* **'exact_answer_after_last' Token:**
* Layer 2: ~0.85
* Layer 4: ~0.85
* Layer 6: ~0.8
* Layer 8: ~0.75
* Layer 10: ~0.7
* Layer 12: ~0.65
* Layer 14: ~0.6
* Layer 16: ~0.55
* Layer 18: ~0.55
* Layer 20: ~0.55
* Layer 22: ~0.6
* Layer 24: ~0.65
* Layer 26: ~0.7
* Layer 28: ~0.75
* Layer 30: ~0.8
* **Tokens -8 to -1:** Generally show lower activation values, ranging from approximately 0.55 to 0.75, with some variation across layers. There appears to be a slight increase in activation for these tokens in the later layers (26-30).
### Key Observations
* The initial layers (2-6) exhibit consistently high activation values (close to 1.0) across all tokens.
* Activation values generally decrease as the layer number increases, particularly for the 'last_q' token.
* The 'exact_answer' tokens ('first', 'last', 'after_last') show a similar activation pattern, slightly lower than 'last_q' in the initial layers.
* The tokens -8 to -1 consistently have the lowest activation values.
* There's a subtle trend of increasing activation for the -8 to -1 tokens in the deeper layers (26-30).
### Interpretation
This heatmap likely represents the attention weights or activation strengths of different layers in a transformer model when processing a sequence of tokens. The high activation in the early layers suggests that these layers are capturing general features of the input sequence. The decreasing activation in later layers, particularly for the 'last_q' token, could indicate that the model is focusing on more specific features or refining its representation of the input.
The lower activation values for the -8 to -1 tokens suggest that these tokens are less relevant to the task the model is performing. The slight increase in activation for these tokens in the deeper layers could indicate that the model is still attempting to extract some information from them, or that these tokens become more relevant in the context of the entire sequence.
The distinct activation patterns for the 'exact_answer' tokens suggest that the model is paying attention to these specific parts of the input sequence when generating an answer. The heatmap provides valuable insights into how the model processes information and makes predictions. The heatmap suggests that the model is focusing on the 'last_q' token more than the 'exact_answer' tokens in the initial layers, but this focus shifts as the information propagates through the network.