TECHNICAL ASSET FINGERPRINT
18fb5adde0c052c357145432
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
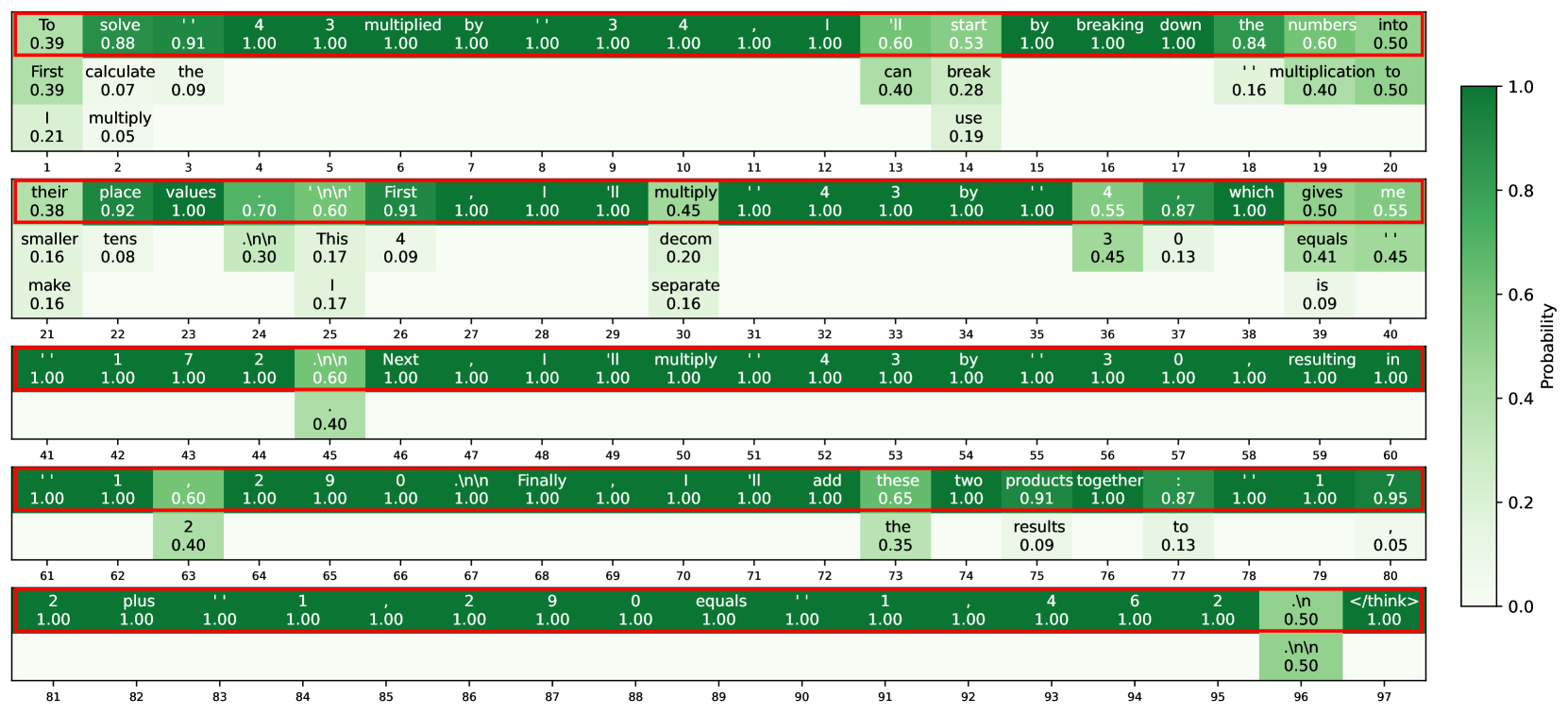
## Heatmap Visualization: Token Probability Analysis of Mathematical Reasoning
### Overview
The image displays a heatmap visualization of token probabilities from what appears to be a language model's reasoning trace for solving a mathematical problem. The visualization is structured as a series of horizontal rows, each containing a sequence of text tokens (words, punctuation, numbers) with associated probability values. The color intensity of each cell corresponds to the probability, with a color scale bar on the right indicating the mapping from probability (0.0 to 1.0) to color (light green to dark green). Several cells are outlined with a red border, likely indicating tokens of particular interest or high confidence.
### Components/Axes
* **X-Axis (Horizontal):** Represents the sequential position of tokens within the reasoning trace. The axis is numbered from 1 to 97, but the numbers are distributed across multiple rows. Each row displays a segment of the sequence (e.g., Row 1: positions 1-20, Row 2: 21-40, etc.).
* **Y-Axis (Vertical):** Not explicitly labeled, but each horizontal row represents a contiguous segment of the token sequence.
* **Cell Content:** Each cell contains two lines of text:
* **Top Line:** The text token (e.g., "To", "solve", "4", "multiply", "\n\n").
* **Bottom Line:** A numerical probability value (e.g., 0.39, 0.88, 1.00).
* **Color Scale/Legend:** Located on the far right. It is a vertical bar labeled "Probability" with a gradient from light green (0.0) to dark green (1.0). Key markers are at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Highlighting:** A red rectangular border surrounds specific cells or groups of cells, drawing attention to them.
### Detailed Analysis
The heatmap visualizes the probability distribution over possible next tokens at each step of generating a mathematical explanation. The text appears to be a step-by-step solution to a multiplication problem (likely 43 * 43, based on the content).
**Row 1 (Positions 1-20):**
* **Tokens & Probabilities:** To (0.39), solve (0.88), ' (0.91), 4 (1.00), 3 (1.00), multiplied (1.00), by (1.00), ' (1.00), 4 (1.00), 3 (1.00), , (1.00), I (1.00), 'll (0.60), start (0.53), by (1.00), breaking (1.00), down (1.00), the (0.84), numbers (0.60), into (0.50).
* **Additional Tokens Below:** First (0.39), calculate (0.07), the (0.09), can (0.40), break (0.28), ' (0.16), multiplication (0.40), to (0.50), I (0.21), multiply (0.05), use (0.19).
* **Observation:** The initial tokens of the sentence have high probability (many 1.00), indicating high model confidence. The red border encloses the entire first row. Tokens below the main line show alternative, lower-probability continuations.
**Row 2 (Positions 21-40):**
* **Tokens & Probabilities:** their (0.38), place (0.92), values (1.00), . (0.70), \n\n (0.60), First (0.91), , (1.00), I (1.00), 'll (1.00), multiply (0.45), ' (1.00), 4 (1.00), 3 (1.00), by (1.00), ' (1.00), 4 (0.55), , (0.87), which (1.00), gives (0.50), me (0.55).
* **Additional Tokens Below:** smaller (0.16), tens (0.08), .\n\n (0.30), This (0.17), 4 (0.09), decom (0.20), 3 (0.45), 0 (0.13), equals (0.41), ' (0.45), make (0.16), I (0.17), separate (0.16), is (0.09).
* **Observation:** The red border encloses the main line of tokens. The model shows high confidence for "place values" and the start of the next step ("First, I'll multiply"). The token "multiply" has a notably lower probability (0.45) compared to its surrounding context.
**Row 3 (Positions 41-60):**
* **Tokens & Probabilities:** ' (1.00), 1 (1.00), 7 (1.00), 2 (1.00), .\n\n (0.60), Next (1.00), , (1.00), I (1.00), 'll (1.00), multiply (1.00), ' (1.00), 4 (1.00), 3 (1.00), by (1.00), ' (1.00), 3 (1.00), 0 (1.00), , (1.00), resulting (1.00), in (1.00).
* **Additional Tokens Below:** . (0.40).
* **Observation:** This row shows extremely high confidence, with almost all tokens having a probability of 1.00. The red border encloses the entire row. The text describes multiplying 43 by 30.
**Row 4 (Positions 61-80):**
* **Tokens & Probabilities:** ' (1.00), 1 (1.00), , (0.60), 2 (1.00), 9 (1.00), 0 (1.00), .\n\n (1.00), Finally (1.00), , (1.00), I (1.00), 'll (1.00), add (1.00), these (0.65), two (1.00), products (0.91), together (1.00), : (0.87), ' (1.00), 1 (1.00), 7 (0.95).
* **Additional Tokens Below:** 2 (0.40), the (0.35), results (0.09), to (0.13), , (0.05).
* **Observation:** The red border encloses the main line. Confidence remains very high for the core action words ("Finally", "I'll", "add") and numbers. The token "these" has a lower probability (0.65).
**Row 5 (Positions 81-97):**
* **Tokens & Probabilities:** 2 (1.00), plus (1.00), ' (1.00), 1 (1.00), , (1.00), 2 (1.00), 9 (1.00), 0 (1.00), equals (1.00), ' (1.00), 1 (1.00), , (1.00), 4 (1.00), 6 (1.00), 2 (1.00), .\n (0.50), </think> (1.00).
* **Additional Tokens Below:** .\n\n (0.50).
* **Observation:** The final row, enclosed in a red border, shows the conclusion of the calculation (1722 + 1290 = 3012) and the end-of-thought token `</think>`. All core tokens have a probability of 1.00, indicating definitive model confidence in the final result.
### Key Observations
1. **High Confidence in Core Reasoning:** The model exhibits very high probability (often 1.00) for the key nouns, verbs, and numbers that form the backbone of the mathematical procedure (e.g., "multiply", "add", "43", "30", "equals").
2. **Lower Confidence in Function Words & Alternatives:** Tokens like "I'll", "start", "these", and punctuation often have lower probabilities (0.50-0.65). The tokens listed *below* the main line in each row represent alternative, lower-probability continuations the model considered.
3. **Structured Problem-Solving:** The text follows a clear, logical structure: stating the problem, breaking it down into sub-problems (43*43, 43*30), performing the multiplications, and finally adding the partial products.
4. **Visual Emphasis:** The red borders consistently highlight the primary, high-probability token sequence that constitutes the model's chosen reasoning path.
5. **Newline Tokens:** The presence of `\n` and `\n\n` tokens indicates the model is generating formatted text with paragraph breaks.
### Interpretation
This heatmap is a diagnostic visualization of a language model's internal reasoning process. It reveals not just *what* the model says, but *how confidently* it selects each word.
* **What it demonstrates:** The model has a strong, confident grasp of the procedural steps for multi-digit multiplication. Its highest confidence is reserved for the factual, operational components of the solution (numbers, arithmetic operators). The lower confidence in connective phrases ("I'll start by", "these two") suggests these are more flexible, stylistic choices where multiple phrasings are plausible.
* **Relationship between elements:** The color gradient provides an immediate visual map of certainty. The spatial layout (sequential tokens on the x-axis) maps directly to the temporal flow of the generated text. The red border acts as a "trace" of the model's final decision path through the space of possible tokens.
* **Notable patterns:** The near-perfect confidence (1.00) in the final answer (`3012`) and the `</think>` token is significant. It shows the model reaches a state of certainty at the conclusion of its reasoning. The pattern of high confidence in content words versus lower confidence in function words is a common characteristic of language model generation.
* **Underlying significance:** This type of visualization is crucial for AI interpretability. It allows developers to audit the model's reasoning, identify points of uncertainty or potential error (e.g., if a critical number had low probability), and understand how it constructs complex, multi-step answers. The image essentially provides a "confidence transcript" of a mathematical proof generated by an AI.
DECODING INTELLIGENCE...