## Line Charts: Model Performance Comparison
### Overview
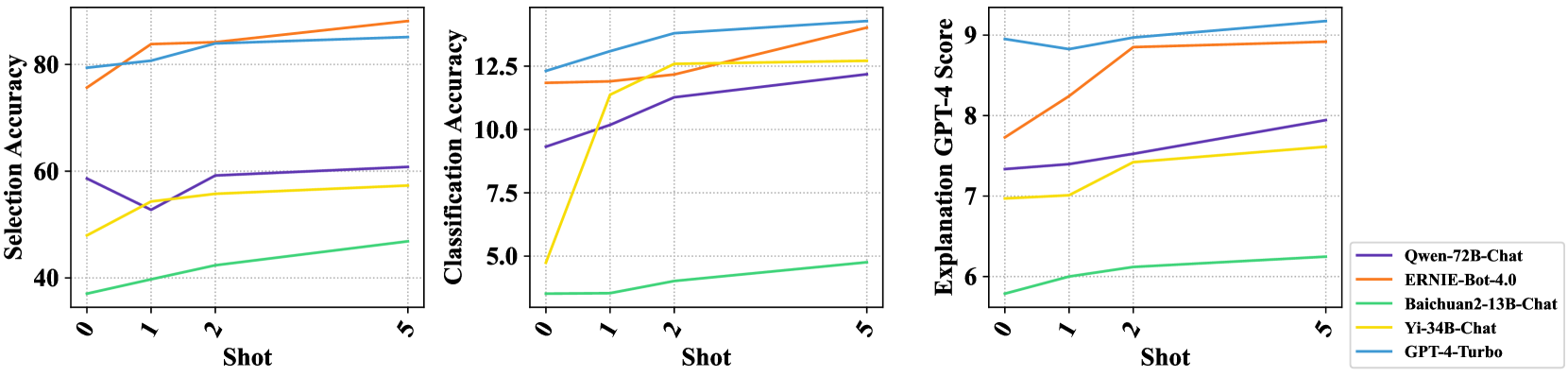
The image contains three line charts comparing the performance of five different language models (Qwen-72B-Chat, ERNIE-Bot-4.0, Baichuan2-13B-Chat, Yi-34B-Chat, and GPT-4-Turbo) across different "shots" (likely referring to few-shot learning scenarios). The charts measure Selection Accuracy, Classification Accuracy, and Explanation GPT-4 Score.
### Components/Axes
* **X-axis (all charts):** "Shot" with values 0, 1, 2, and 5.
* **Y-axis (left chart):** "Selection Accuracy" with a scale from 40 to 80.
* **Y-axis (middle chart):** "Classification Accuracy" with a scale from 5.0 to 12.5.
* **Y-axis (right chart):** "Explanation GPT-4 Score" with a scale from 6 to 9.
* **Legend (bottom-right):**
* Purple: Qwen-72B-Chat
* Orange: ERNIE-Bot-4.0
* Green: Baichuan2-13B-Chat
* Yellow: Yi-34B-Chat
* Blue: GPT-4-Turbo
### Detailed Analysis
**Chart 1: Selection Accuracy**
* **Qwen-72B-Chat (Purple):** Starts at approximately 60 at Shot 0, decreases to approximately 53 at Shot 1, then increases to approximately 60 at Shot 2, and remains relatively stable at Shot 5.
* **ERNIE-Bot-4.0 (Orange):** Starts at approximately 72 at Shot 0, increases to approximately 80 at Shot 1, and continues to increase to approximately 85 at Shot 5.
* **Baichuan2-13B-Chat (Green):** Starts at approximately 37 at Shot 0, increases steadily to approximately 45 at Shot 5.
* **Yi-34B-Chat (Yellow):** Starts at approximately 50 at Shot 0, increases sharply to approximately 58 at Shot 1, and then remains relatively stable around 58-60 at Shot 5.
* **GPT-4-Turbo (Blue):** Starts at approximately 78 at Shot 0, increases slightly to approximately 80 at Shot 1, and continues to increase to approximately 83 at Shot 5.
**Chart 2: Classification Accuracy**
* **Qwen-72B-Chat (Purple):** Starts at approximately 9 at Shot 0, increases to approximately 11 at Shot 2, and continues to increase to approximately 12 at Shot 5.
* **ERNIE-Bot-4.0 (Orange):** Starts at approximately 12 at Shot 0, increases slightly to approximately 12.5 at Shot 1, and remains relatively stable around 13 at Shot 5.
* **Baichuan2-13B-Chat (Green):** Starts at approximately 3.5 at Shot 0, increases steadily to approximately 4.8 at Shot 5.
* **Yi-34B-Chat (Yellow):** Starts at approximately 8 at Shot 0, increases sharply to approximately 11 at Shot 1, and then increases slightly to approximately 11.5 at Shot 5.
* **GPT-4-Turbo (Blue):** Starts at approximately 12 at Shot 0, increases to approximately 13 at Shot 2, and continues to increase to approximately 13.5 at Shot 5.
**Chart 3: Explanation GPT-4 Score**
* **Qwen-72B-Chat (Purple):** Starts at approximately 7.5 at Shot 0, increases to approximately 8.5 at Shot 2, and continues to increase to approximately 8.7 at Shot 5.
* **ERNIE-Bot-4.0 (Orange):** Starts at approximately 7.8 at Shot 0, increases to approximately 8.8 at Shot 2, and continues to increase to approximately 9.2 at Shot 5.
* **Baichuan2-13B-Chat (Green):** Starts at approximately 5.5 at Shot 0, increases steadily to approximately 6 at Shot 5.
* **Yi-34B-Chat (Yellow):** Starts at approximately 7 at Shot 0, remains relatively stable around 7.2 at Shot 5.
* **GPT-4-Turbo (Blue):** Starts at approximately 9 at Shot 0, decreases slightly to approximately 8.8 at Shot 1, and then remains relatively stable around 8.8 at Shot 5.
### Key Observations
* GPT-4-Turbo and ERNIE-Bot-4.0 generally perform well across all three metrics.
* Baichuan2-13B-Chat consistently shows the lowest performance.
* Yi-34B-Chat shows a significant jump in performance from Shot 0 to Shot 1 in Classification Accuracy.
* Qwen-72B-Chat shows a dip in Selection Accuracy from Shot 0 to Shot 1.
### Interpretation
The charts provide a comparative analysis of the performance of different language models in few-shot learning scenarios. The "Shot" likely refers to the number of examples provided to the model during training or evaluation. The metrics (Selection Accuracy, Classification Accuracy, and Explanation GPT-4 Score) measure different aspects of the model's performance.
The data suggests that GPT-4-Turbo and ERNIE-Bot-4.0 are the top-performing models overall. Baichuan2-13B-Chat consistently lags behind the other models. The performance trends indicate how each model's accuracy and scoring change as the number of provided examples (shots) increases. The initial jump in performance for Yi-34B-Chat in Classification Accuracy suggests that it benefits significantly from even a single example. The dip in Qwen-72B-Chat's Selection Accuracy from Shot 0 to Shot 1 could indicate an initial overfitting or adjustment period.