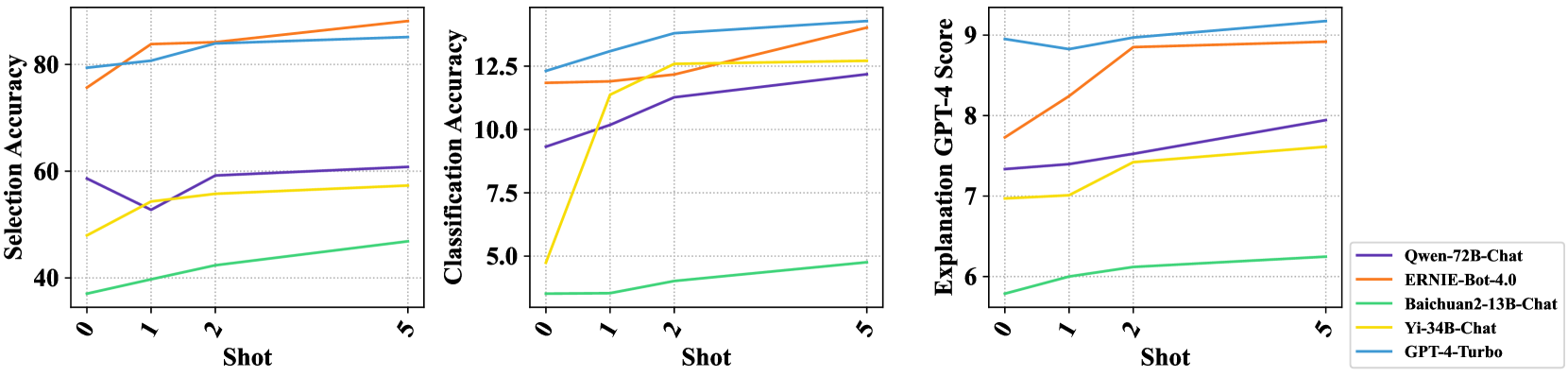
## Charts: Model Performance Comparison
### Overview
The image presents three line charts comparing the performance of five different language models (Qwen-72B-Chat, ERNIE-Bot-4.0, Baichuan2-13B-Chat, Yi-34B-Chat, and GPT-4-Turbo) across three different metrics: Selection Accuracy, Classification Accuracy, and Explanation GPT-4 Score. The performance is evaluated at 0-shot, 1-shot, 2-shot, and 5-shot settings.
### Components/Axes
Each chart shares a common x-axis labeled "Shot" with markers at 0, 1, 2, and 5.
* **Chart 1 (Left):** Y-axis labeled "Selection Accuracy (%)" ranging from 0 to 80.
* **Chart 2 (Center):** Y-axis labeled "Classification Accuracy" ranging from 0 to 12.5.
* **Chart 3 (Right):** Y-axis labeled "Explanation GPT-4 Score" ranging from 6 to 9.
The legend, positioned at the top-right of all three charts, identifies the models using both name and color:
* Qwen-72B-Chat (Purple)
* ERNIE-Bot-4.0 (Orange)
* Baichuan2-13B-Chat (Black)
* Yi-34B-Chat (Green)
* GPT-4-Turbo (Teal/Cyan)
### Detailed Analysis
**Chart 1: Selection Accuracy**
* **Qwen-72B-Chat (Purple):** Starts at approximately 72%, dips to around 60% at 1-shot, then rises to approximately 82% at 2-shot and remains relatively stable at around 84% at 5-shot.
* **ERNIE-Bot-4.0 (Orange):** Starts at approximately 78%, increases to around 84% at 1-shot, then remains relatively stable at around 86% at 2-shot and 5-shot.
* **Baichuan2-13B-Chat (Black):** Starts at approximately 50%, increases to around 62% at 1-shot, then rises to approximately 70% at 2-shot and remains relatively stable at around 72% at 5-shot.
* **Yi-34B-Chat (Green):** Starts at approximately 30%, increases sharply to around 68% at 1-shot, then rises to approximately 78% at 2-shot and remains relatively stable at around 80% at 5-shot.
* **GPT-4-Turbo (Teal/Cyan):** Starts at approximately 80%, dips slightly to around 76% at 1-shot, then rises to approximately 88% at 2-shot and remains relatively stable at around 88% at 5-shot.
**Chart 2: Classification Accuracy**
* **Qwen-72B-Chat (Purple):** Starts at approximately 2.5, increases sharply to around 11 at 1-shot, then rises to approximately 12.5 at 2-shot and remains relatively stable at around 12.5 at 5-shot.
* **ERNIE-Bot-4.0 (Orange):** Starts at approximately 5, increases sharply to around 12 at 1-shot, then remains relatively stable at around 12.5 at 2-shot and 5-shot.
* **Baichuan2-13B-Chat (Black):** Starts at approximately 2.5, increases to around 6 at 1-shot, then rises to approximately 8 at 2-shot and remains relatively stable at around 8 at 5-shot.
* **Yi-34B-Chat (Green):** Starts at approximately 0, increases sharply to around 5 at 1-shot, then rises to approximately 10 at 2-shot and remains relatively stable at around 10 at 5-shot.
* **GPT-4-Turbo (Teal/Cyan):** Starts at approximately 7.5, increases slightly to around 8 at 1-shot, then rises to approximately 9 at 2-shot and remains relatively stable at around 9 at 5-shot.
**Chart 3: Explanation GPT-4 Score**
* **Qwen-72B-Chat (Purple):** Starts at approximately 7.5, increases to around 8.2 at 1-shot, then remains relatively stable at around 8.2 at 2-shot and 5-shot.
* **ERNIE-Bot-4.0 (Orange):** Starts at approximately 8.5, decreases slightly to around 8.3 at 1-shot, then remains relatively stable at around 8.3 at 2-shot and 5-shot.
* **Baichuan2-13B-Chat (Black):** Starts at approximately 6.5, increases to around 7.5 at 1-shot, then rises to approximately 8 at 2-shot and remains relatively stable at around 8 at 5-shot.
* **Yi-34B-Chat (Green):** Starts at approximately 6.5, increases to around 7.5 at 1-shot, then rises to approximately 8 at 2-shot and remains relatively stable at around 8 at 5-shot.
* **GPT-4-Turbo (Teal/Cyan):** Starts at approximately 8.8, decreases slightly to around 8.6 at 1-shot, then remains relatively stable at around 8.6 at 2-shot and 5-shot.
### Key Observations
* GPT-4-Turbo consistently achieves the highest Selection Accuracy and remains competitive in Classification Accuracy and Explanation GPT-4 Score.
* ERNIE-Bot-4.0 shows strong performance across all metrics, often rivaling GPT-4-Turbo.
* Yi-34B-Chat demonstrates significant improvement with increasing shot counts, particularly in Classification Accuracy.
* Baichuan2-13B-Chat generally exhibits the lowest performance across all metrics, but still shows improvement with more shots.
* The performance of most models plateaus after 2-shot learning.
### Interpretation
The charts demonstrate the impact of few-shot learning on the performance of different language models across various tasks. The consistent high performance of GPT-4-Turbo suggests its superior capabilities in understanding and responding to prompts, even with limited examples. The improvements observed in other models with increasing shot counts highlight the importance of providing contextual information to enhance their performance. The plateauing effect after 2-shot learning suggests that the models reach a point of diminishing returns, where additional examples do not significantly improve their accuracy or explanation quality. The differences in performance between models indicate varying levels of pre-training data, model architecture, and fine-tuning strategies. The use of GPT-4 as a scoring mechanism for explanations introduces a potential bias, as the models are being evaluated against a benchmark set by GPT-4 itself.