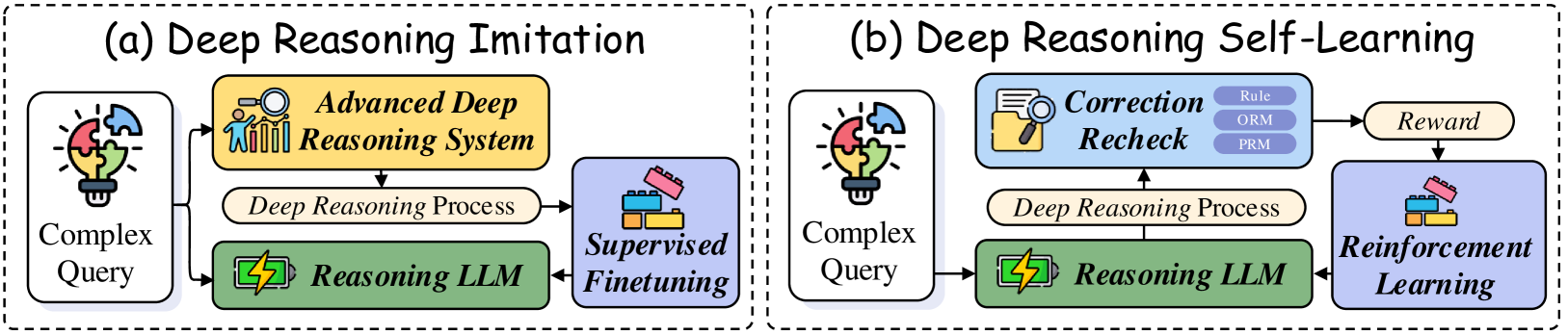
## Flowchart Diagram: Deep Reasoning Architectures
### Overview
The image presents two side-by-side diagrams comparing two approaches to deep reasoning systems:
- **(a) Deep Reasoning Imitation**: A linear pipeline with supervised finetuning.
- **(b) Deep Reasoning Self-Learning**: A feedback-driven system with reinforcement learning and iterative correction.
### Components/Axes
#### Diagram (a): Deep Reasoning Imitation
1. **Input**:
- **Complex Query** (icon: puzzle pieces with lightbulb).
2. **Process**:
- **Advanced Deep Reasoning System** (icon: magnifying glass over bar charts).
- **Deep Reasoning Process** (text label).
3. **Output**:
- **Supervised Finetuning** (icon: Lego blocks).
- **Reasoning LLM** (icon: battery with lightning bolt).
#### Diagram (b): Deep Reasoning Self-Learning
1. **Input**:
- **Complex Query** (same icon as (a)).
2. **Process**:
- **Correction Recheck** (icon: folder with magnifying glass; sub-components: **Rule**, **ORM**, **PRM**).
- **Deep Reasoning Process** (same text label as (a)).
3. **Output**:
- **Reinforcement Learning** (icon: Lego blocks with upward arrow).
- **Reward** (text label).
### Detailed Analysis
- **Diagram (a)**:
- The flow is linear: Complex Query → Advanced System → Deep Reasoning Process → Supervised Finetuning/Reasoning LLM.
- **Supervised Finetuning** is explicitly labeled, suggesting reliance on labeled data for improvement.
- **Diagram (b)**:
- Introduces a **Correction Recheck** step with three sub-components (**Rule**, **ORM**, **PRM**), implying iterative validation.
- **Reinforcement Learning** replaces Supervised Finetuning, with a **Reward** signal feeding back into the system.
### Key Observations
1. **Structural Difference**:
- (a) uses a one-way pipeline; (b) incorporates feedback loops via **Reward**.
2. **Correction Mechanism**:
- (b) emphasizes error correction through **Rule**, **ORM**, and **PRM**, which are not present in (a).
3. **LLM Role**:
- Both diagrams end with **Reasoning LLM**, but (b) integrates it into a self-improving loop.
### Interpretation
- **Imitation vs. Self-Learning**:
- Diagram (a) mimics human reasoning via supervised methods, while (b) enables autonomous improvement through reinforcement learning.
- **Correction Recheck**:
- The inclusion of **Rule**, **ORM**, and **PRM** in (b) suggests a focus on robustness, addressing potential errors in the reasoning process.
- **Reward Signal**:
- The **Reward** in (b) likely quantifies the quality of outputs, driving iterative refinement. This contrasts with (a)’s static finetuning.
- **Implications**:
- (b) may outperform (a) in dynamic environments requiring adaptability, but at the cost of increased computational complexity due to feedback loops.
## Notes
- No numerical data or axes are present; the diagrams focus on architectural design.
- Colors (e.g., yellow for "Advanced System," blue for "Correction Recheck") are used for visual distinction but lack a formal legend.
- Both diagrams share the **Complex Query** and **Reasoning LLM** components, highlighting their shared foundation.