## Diagram: Deep Reasoning Imitation vs. Self-Learning
### Overview
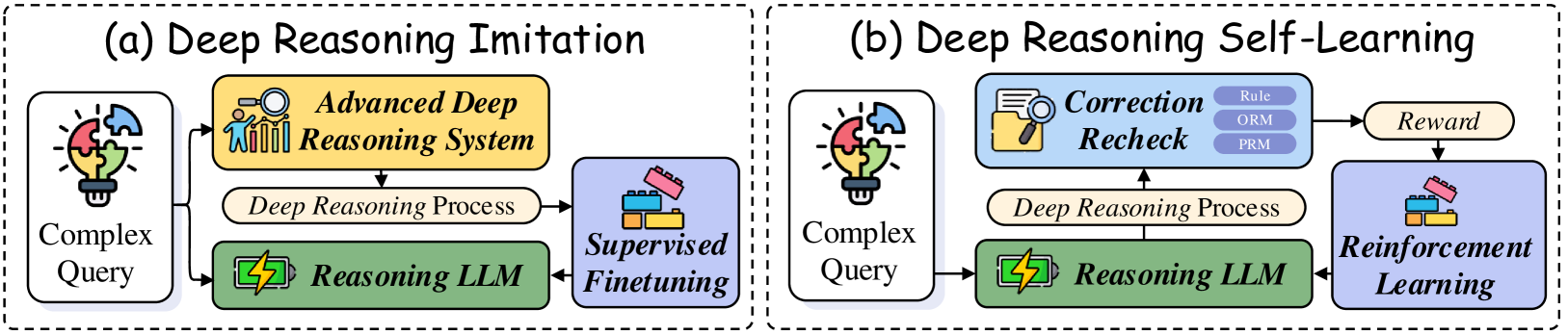
The image presents two diagrams illustrating different approaches to deep reasoning: Deep Reasoning Imitation (a) and Deep Reasoning Self-Learning (b). Both diagrams depict a flow of processes, starting with a "Complex Query" and leading to either "Supervised Finetuning" or "Reinforcement Learning."
### Components/Axes
**Diagram (a): Deep Reasoning Imitation**
* **Title:** (a) Deep Reasoning Imitation
* **Input:** Complex Query (represented by a lightbulb with puzzle pieces)
* **Process 1:** Advanced Deep Reasoning System (yellow box with an icon of people and a magnifying glass)
* **Process Flow:** Deep Reasoning Process (tan box)
* **Process 2:** Reasoning LLM (green box with a battery icon)
* **Output:** Supervised Finetuning (blue box with building blocks icon)
**Diagram (b): Deep Reasoning Self-Learning**
* **Title:** (b) Deep Reasoning Self-Learning
* **Input:** Complex Query (represented by a lightbulb with puzzle pieces)
* **Process 1:** Reasoning LLM (green box with a battery icon)
* **Process Flow:** Deep Reasoning Process (tan box)
* **Process 2:** Correction Recheck (light blue box with a magnifying glass over a document icon). Contains sub-elements: Rule, ORM, PRM (light purple boxes).
* **Reward:** Reward (tan box)
* **Output:** Reinforcement Learning (blue box with building blocks icon)
### Detailed Analysis or Content Details
**Diagram (a): Deep Reasoning Imitation**
1. **Complex Query:** The process begins with a complex query, visually represented by a lightbulb made of puzzle pieces.
2. **Advanced Deep Reasoning System:** The query is then processed by an advanced deep reasoning system.
3. **Deep Reasoning Process:** The output of the advanced system undergoes a deep reasoning process.
4. **Reasoning LLM:** The result is fed into a reasoning LLM (Language Learning Model).
5. **Supervised Finetuning:** Finally, the LLM's output is used for supervised finetuning.
**Diagram (b): Deep Reasoning Self-Learning**
1. **Complex Query:** Similar to (a), the process starts with a complex query.
2. **Reasoning LLM:** The query is processed by a reasoning LLM.
3. **Deep Reasoning Process:** The output of the LLM undergoes a deep reasoning process.
4. **Correction Recheck:** The result is then fed into a correction recheck module, which includes Rule, ORM, and PRM components.
5. **Reward:** The correction recheck module provides a reward signal.
6. **Reinforcement Learning:** The reward signal is used for reinforcement learning.
### Key Observations
* Both diagrams start with a "Complex Query" and involve a "Reasoning LLM" and a "Deep Reasoning Process."
* Diagram (a) uses an "Advanced Deep Reasoning System" and "Supervised Finetuning," while diagram (b) uses "Correction Recheck," "Reward," and "Reinforcement Learning."
* Diagram (b) includes a feedback loop from the "Correction Recheck" module back to the "Reasoning LLM" via the "Deep Reasoning Process."
### Interpretation
The diagrams illustrate two distinct approaches to deep reasoning. Deep Reasoning Imitation (a) relies on an advanced system and supervised learning, suggesting a more guided or pre-defined learning process. Deep Reasoning Self-Learning (b) uses a reinforcement learning approach, where the system learns through trial and error, guided by a reward signal derived from a correction recheck module. The presence of Rule, ORM, and PRM within the "Correction Recheck" module suggests different methods or criteria used for evaluating and correcting the LLM's reasoning process. The self-learning approach implies a more autonomous and adaptive learning process compared to the imitation approach.