\n
## Diagram: Deep Reasoning Frameworks
### Overview
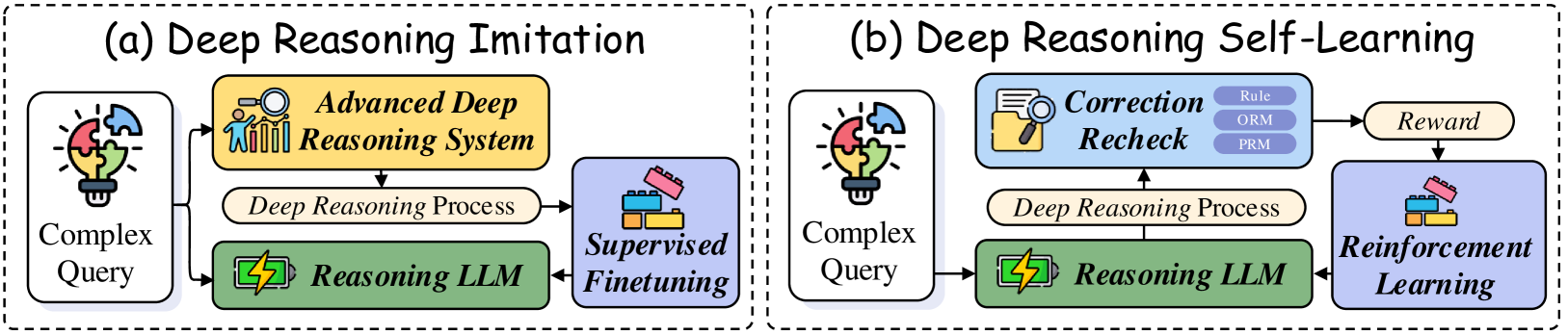
The image presents a comparative diagram illustrating two deep reasoning frameworks: (a) Deep Reasoning Imitation and (b) Deep Reasoning Self-Learning. Both frameworks share a similar structure but differ in their feedback and learning mechanisms. The diagram uses a flowchart-like representation with rounded rectangles representing processes and arrows indicating the flow of information.
### Components/Axes
The diagram consists of two main sections, labeled "(a) Deep Reasoning Imitation" and "(b) Deep Reasoning Self-Learning". Each section contains the following components:
* **Complex Query:** Input to the system, represented by a lightbulb with puzzle pieces.
* **Reasoning LLM:** A green rectangle labeled "Reasoning LLM".
* **Deep Reasoning Process:** A blue rectangle labeled "Deep Reasoning Process".
* **Output/Feedback:** The final stage, differing between the two frameworks.
* **(a) Imitation:** "Supervised Finetuning" with a laptop icon.
* **(b) Self-Learning:** "Reinforcement Learning" with a robot icon and a "Reward" box, and a "Correction Recheck" box containing "Rule ORM PRM".
### Detailed Analysis or Content Details
**Framework (a) - Deep Reasoning Imitation:**
1. A "Complex Query" (lightbulb with puzzle pieces) initiates the process.
2. The query is fed into the "Reasoning LLM" (green rectangle).
3. The LLM performs a "Deep Reasoning Process" (blue rectangle).
4. The output of the process is used for "Supervised Finetuning" (laptop icon). An arrow loops back from "Supervised Finetuning" to the "Reasoning LLM", indicating iterative improvement.
5. An arrow also connects the "Deep Reasoning Process" to the "Advanced Deep Reasoning System" (yellow rectangle with gears and a brain).
**Framework (b) - Deep Reasoning Self-Learning:**
1. A "Complex Query" (lightbulb with puzzle pieces) initiates the process.
2. The query is fed into the "Reasoning LLM" (green rectangle).
3. The LLM performs a "Deep Reasoning Process" (blue rectangle).
4. The output of the process is subjected to "Correction Recheck" (light blue rectangle) containing "Rule ORM PRM".
5. The "Correction Recheck" feeds into a "Reward" box (green rectangle).
6. The "Reward" is used for "Reinforcement Learning" (robot icon). An arrow loops back from "Reinforcement Learning" to the "Reasoning LLM", indicating iterative improvement.
7. An arrow also connects the "Deep Reasoning Process" to the "Advanced Deep Reasoning System" (yellow rectangle with gears and a brain).
### Key Observations
* Both frameworks utilize a "Reasoning LLM" and a "Deep Reasoning Process" as core components.
* The primary difference lies in the feedback mechanism: "Supervised Finetuning" in Imitation and "Reinforcement Learning" with "Correction Recheck" and "Reward" in Self-Learning.
* The "Advanced Deep Reasoning System" appears to be a higher-level component that receives input from the "Deep Reasoning Process" in both frameworks.
* The "Correction Recheck" box in the Self-Learning framework explicitly mentions "Rule ORM PRM", suggesting these are components of the correction process.
### Interpretation
The diagram illustrates two distinct approaches to building deep reasoning systems. The "Imitation" framework relies on labeled data and supervised learning to refine the reasoning LLM, mimicking expert reasoning. The "Self-Learning" framework, on the other hand, employs reinforcement learning, where the system learns through trial and error, guided by a reward signal and a correction mechanism. The inclusion of "Rule ORM PRM" in the "Correction Recheck" suggests a rule-based component is used to evaluate and correct the reasoning process.
The diagram highlights a shift from traditional supervised learning to more autonomous learning approaches in the field of deep reasoning. The Self-Learning framework represents a more sophisticated approach, potentially enabling the system to discover novel reasoning strategies beyond what is explicitly taught in a supervised setting. The "Advanced Deep Reasoning System" in both diagrams suggests a hierarchical architecture where the LLM's output is further processed or refined by a higher-level system.