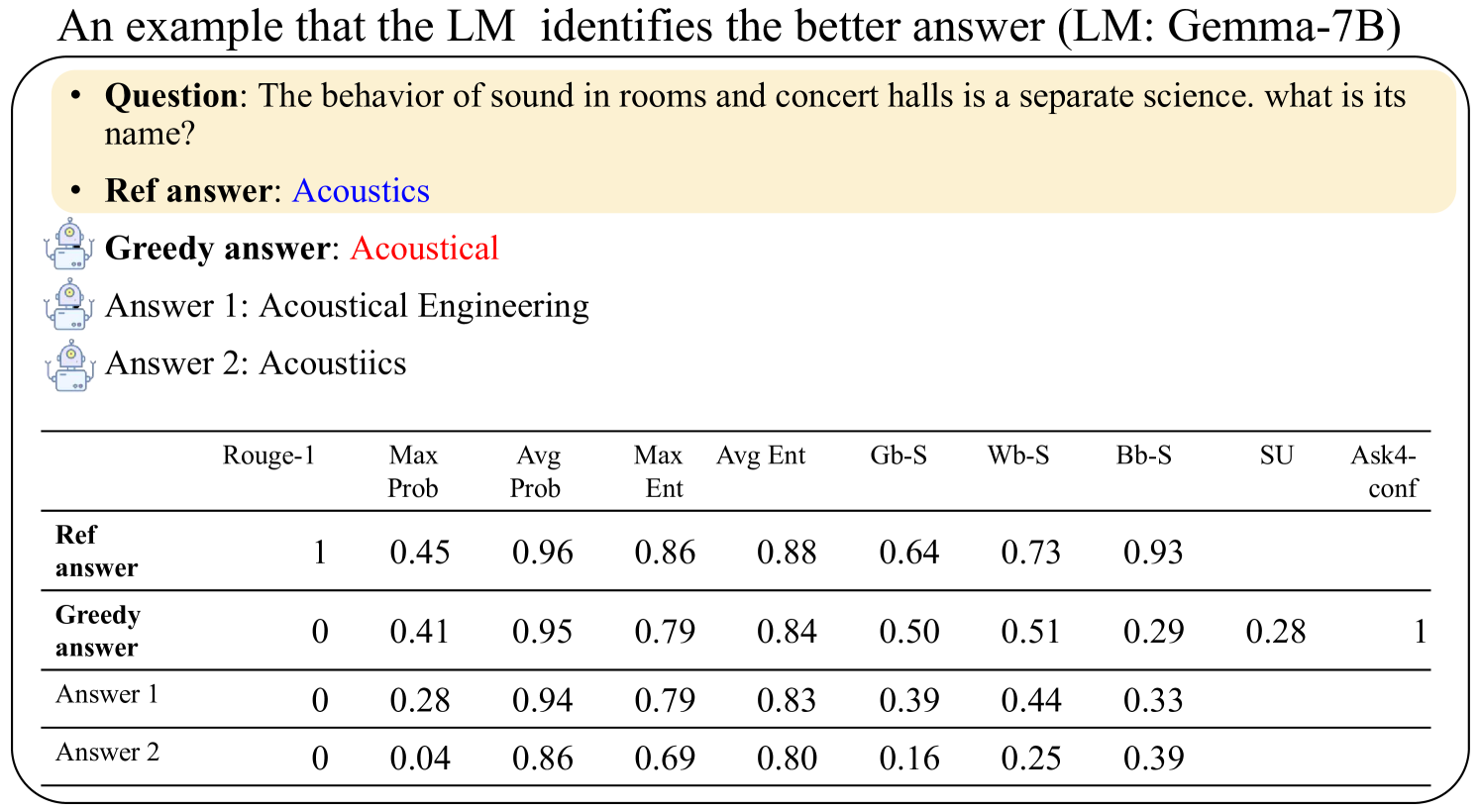
## Chart/Diagram Type: Table with Question/Answer Context
### Overview
The image presents a table comparing the performance of different answers generated by a Language Model (LM), Gemma-7B, against a reference answer. The context is a question about the science related to the behavior of sound in rooms and concert halls. The table provides various metrics for each answer, including ROUGE-1 score, maximum probability (Max Prob), average probability (Avg Prob), maximum entropy (Max Ent), average entropy (Avg Ent), and several other metrics denoted by abbreviations (Gb-S, Wb-S, Bb-S, SU, Ask4-conf).
### Components/Axes
* **Header:** "An example that the LM identifies the better answer (LM: Gemma-7B)"
* **Question Context:**
* Question: "The behavior of sound in rooms and concert halls is a separate science. what is its name?"
* Ref answer: Acoustics
* Greedy answer: Acoustical
* Answer 1: Acoustical Engineering
* Answer 2: Acoustiics
* **Table Columns (Metrics):**
* Rouge-1
* Max Prob
* Avg Prob
* Max Ent
* Avg Ent
* Gb-S
* Wb-S
* Bb-S
* SU
* Ask4-conf
* **Table Rows (Answers):**
* Ref answer
* Greedy answer
* Answer 1
* Answer 2
### Detailed Analysis or ### Content Details
The table contains the following data:
| | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
| :-------------------- | :------ | :------- | :------- | :------ | :------ | :--- | :--- | :--- | :--- | :-------- |
| Ref answer | 1 | 0.45 | 0.96 | 0.86 | 0.88 | 0.64 | 0.73 | 0.93 | | |
| Greedy answer | 0 | 0.41 | 0.95 | 0.79 | 0.84 | 0.50 | 0.51 | 0.29 | 0.28 | 1 |
| Answer 1 | 0 | 0.28 | 0.94 | 0.79 | 0.83 | 0.39 | 0.44 | 0.33 | | |
| Answer 2 | 0 | 0.04 | 0.86 | 0.69 | 0.80 | 0.16 | 0.25 | 0.39 | | |
* **Ref answer (Acoustics):**
* Rouge-1: 1
* Max Prob: 0.45
* Avg Prob: 0.96
* Max Ent: 0.86
* Avg Ent: 0.88
* Gb-S: 0.64
* Wb-S: 0.73
* Bb-S: 0.93
* **Greedy answer (Acoustical):**
* Rouge-1: 0
* Max Prob: 0.41
* Avg Prob: 0.95
* Max Ent: 0.79
* Avg Ent: 0.84
* Gb-S: 0.50
* Wb-S: 0.51
* Bb-S: 0.29
* SU: 0.28
* Ask4-conf: 1
* **Answer 1 (Acoustical Engineering):**
* Rouge-1: 0
* Max Prob: 0.28
* Avg Prob: 0.94
* Max Ent: 0.79
* Avg Ent: 0.83
* Gb-S: 0.39
* Wb-S: 0.44
* Bb-S: 0.33
* **Answer 2 (Acoustiics):**
* Rouge-1: 0
* Max Prob: 0.04
* Avg Prob: 0.86
* Max Ent: 0.69
* Avg Ent: 0.80
* Gb-S: 0.16
* Wb-S: 0.25
* Bb-S: 0.39
### Key Observations
* The "Ref answer" (Acoustics) has a ROUGE-1 score of 1, indicating a perfect match with the reference.
* The "Greedy answer" (Acoustical) has a high average probability (0.95) but a ROUGE-1 score of 0.
* "Answer 2" (Acoustiics) has the lowest maximum probability (0.04) among all answers.
* The "Ref answer" has the highest Bb-S score (0.93).
### Interpretation
The table demonstrates a comparison of different answers generated by the LM (Gemma-7B) to a specific question. The metrics provide insights into the quality and relevance of each answer. The ROUGE-1 score highlights the exact match of the "Ref answer," while other metrics like "Max Prob" and "Avg Prob" indicate the model's confidence in its generated answers. The "Greedy answer," although having a high average probability, fails to match the reference answer, as indicated by its ROUGE-1 score of 0. This suggests that the model might be generating answers that are probable but not necessarily correct. The other answers ("Answer 1" and "Answer 2") also have ROUGE-1 scores of 0, indicating they are incorrect. The Ask4-conf value of 1 for the Greedy answer is interesting, and its meaning is not clear from the context.