\n
## Data Table: LM Answer Evaluation Metrics
### Overview
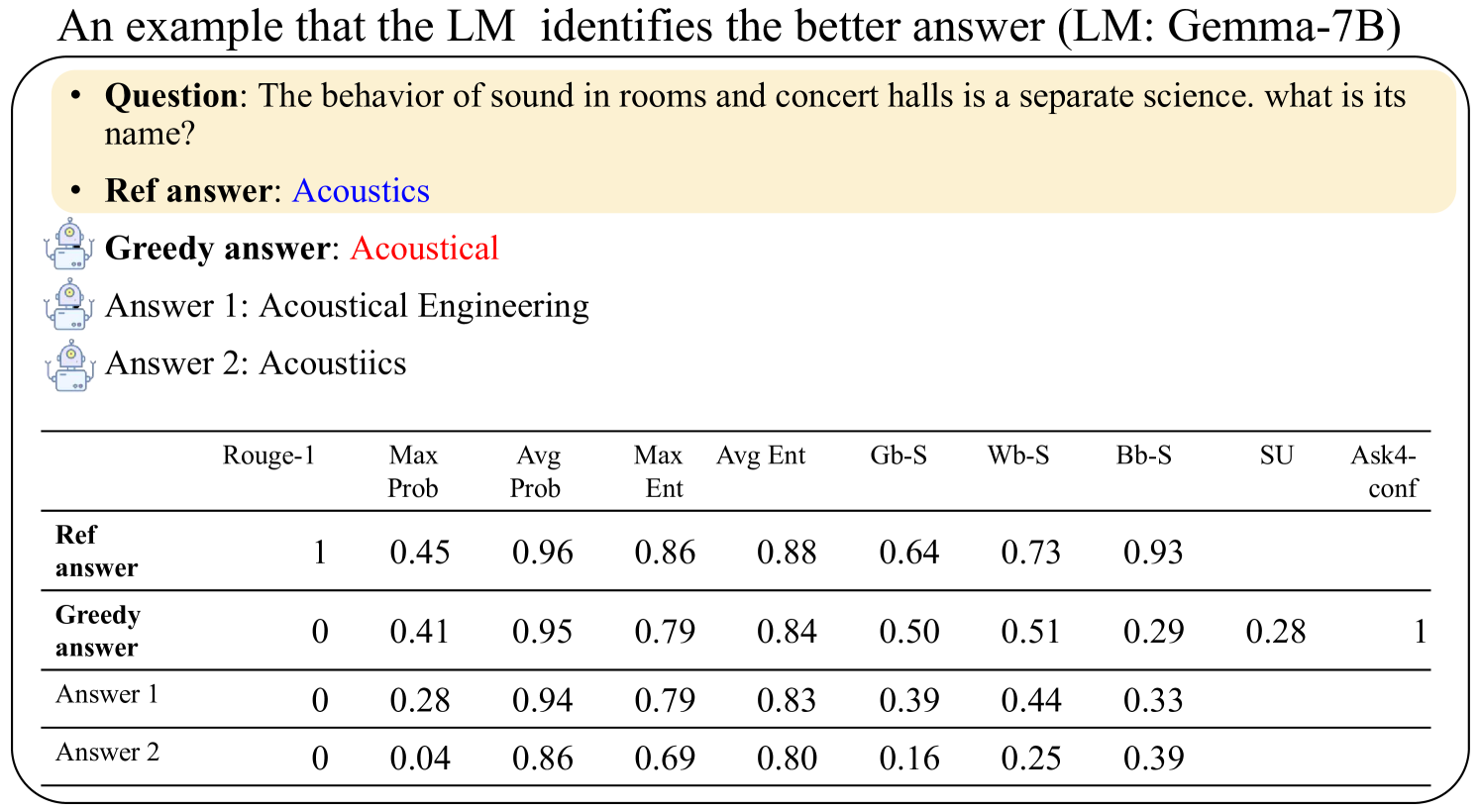
This image presents a data table comparing the performance of different answers generated by a Language Model (LM) – specifically Gemma-7B – against a reference answer, based on several evaluation metrics. The context is a question about the science of sound in rooms and concert halls.
### Components/Axes
The table has the following structure:
* **Rows:** Represent different answers: "Ref answer", "Greedy answer", "Answer 1", and "Answer 2".
* **Columns:** Represent evaluation metrics: "Rouge-1", "Max Prob", "Avg Prob", "Max Ent", "Avg Ent", "Gb-S", "Wb-S", "Bb-S", "SU", and "Ask4-conf".
* **Header:** The top row labels the columns with the metric names.
* **Question:** "The behavior of sound in rooms and concert halls is a separate science. what is its name?"
* **Answers:**
* Ref answer: Acoustics
* Greedy answer: Acoustical
* Answer 1: Acoustical Engineering
* Answer 2: Acoustics
### Detailed Analysis or Content Details
The table contains numerical values representing the scores for each answer across each metric. Here's a breakdown of the data:
| Answer | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
|---------------|---------|----------|----------|---------|---------|------|------|------|-------|-----------|
| Ref answer | 1 | 0.45 | 0.96 | 0.86 | 0.88 | 0.64 | 0.73 | 0.93 | | |
| Greedy answer | 0 | 0.41 | 0.95 | 0.79 | 0.84 | 0.50 | 0.51 | 0.29 | 0.28 | 1 |
| Answer 1 | 0 | 0.28 | 0.94 | 0.79 | 0.83 | 0.39 | 0.44 | 0.33 | | |
| Answer 2 | 0 | 0.04 | 0.86 | 0.69 | 0.80 | 0.16 | 0.25 | 0.39 | | |
**Trends and Observations:**
* **Rouge-1:** The "Ref answer" has a score of 1, while all other answers have a score of 0.
* **Max Prob:** The "Ref answer" has the highest Max Prob (0.45), followed by the "Greedy answer" (0.41).
* **Avg Prob:** All answers have high Avg Prob scores, ranging from 0.86 to 0.96.
* **Max Ent:** The "Ref answer" has the highest Max Ent (0.86).
* **Avg Ent:** All answers have high Avg Ent scores, ranging from 0.80 to 0.88.
* **Gb-S, Wb-S, Bb-S, SU:** The "Ref answer" generally has higher scores in these metrics compared to the other answers, but the differences are less pronounced.
* **Ask4-conf:** The "Greedy answer" has a score of 1, while all other answers have no value.
### Key Observations
The "Ref answer" consistently scores highest in several metrics, indicating it is the most accurate answer according to these evaluations. The "Greedy answer" has a high Ask4-conf score, suggesting high confidence in that answer, but lower scores in other metrics. "Answer 2" consistently has the lowest scores across most metrics.
### Interpretation
This data demonstrates a comparison of different answers generated by a language model against a reference answer. The evaluation metrics provide a quantitative assessment of the quality of each answer. The "Ref answer" is clearly preferred based on the majority of metrics, suggesting the model performs best when directly matching the expected answer. The "Greedy answer" shows a trade-off between confidence and overall accuracy. The varying scores across different metrics highlight the multi-faceted nature of evaluating language model outputs. The data suggests that while the model can generate plausible answers, it doesn't always align with the reference answer, and the confidence level doesn't necessarily correlate with accuracy.