\n
## Technical Document Extraction: Language Model Answer Evaluation Example
### Overview
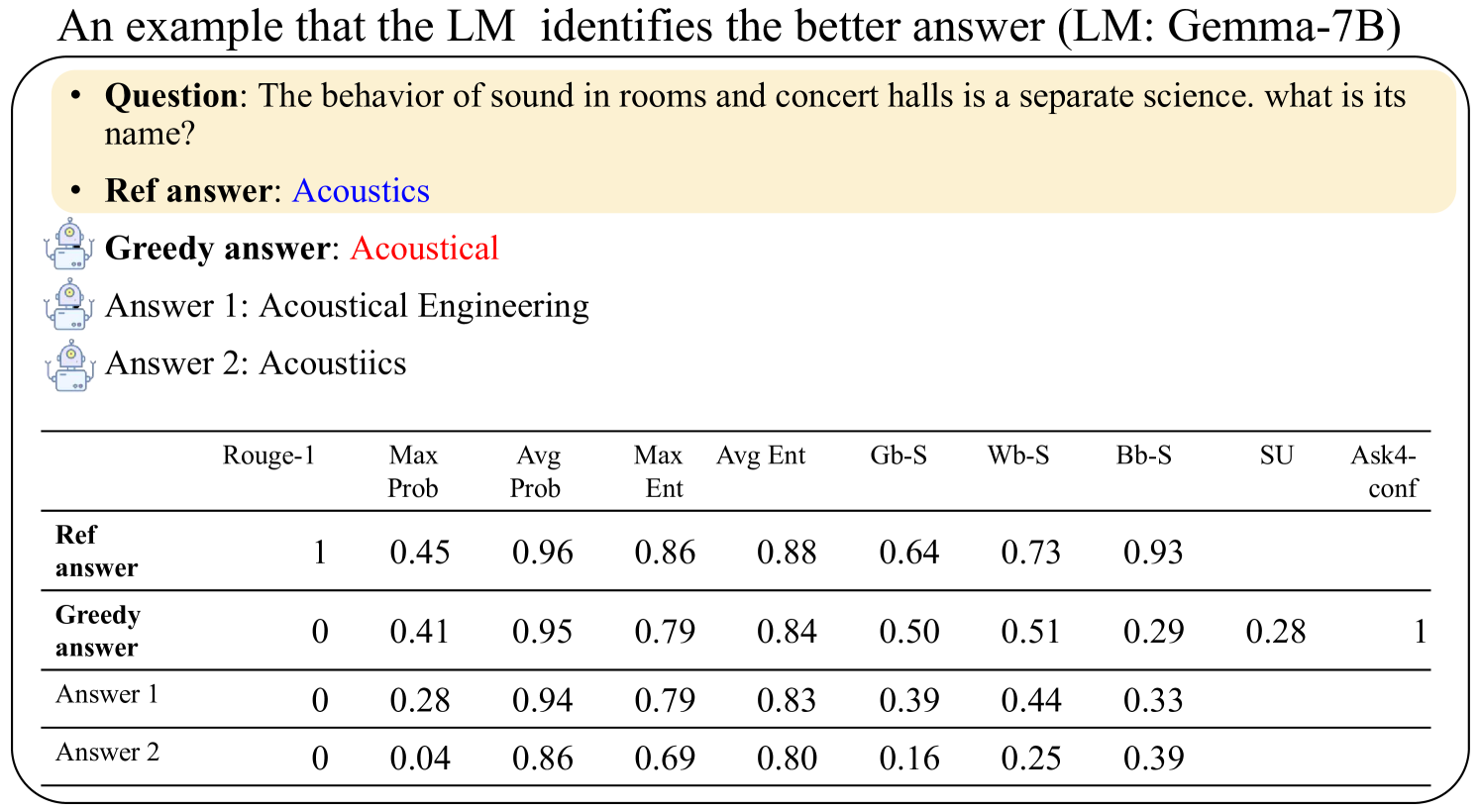
The image is a technical figure demonstrating how a language model (LM) identifies a better answer to a factual question. It presents a question, a reference answer, three alternative model-generated answers, and a table of quantitative metrics comparing them. The example uses the LM "Gemma-7B".
### Components/Axes
The image is structured into two main sections:
1. **Upper Section (Question & Answers):** Contains the question, reference answer, and three alternative answers.
2. **Lower Section (Metrics Table):** A data table comparing the answers across multiple evaluation metrics.
**Textual Content - Upper Section:**
* **Title:** "An example that the LM identifies the better answer (LM: Gemma-7B)"
* **Question Box (Beige Background):**
* **Question:** "The behavior of sound in rooms and concert halls is a separate science. what is its name?"
* **Ref answer:** "Acoustics" (displayed in blue text)
* **Alternative Answers (each preceded by a small robot icon):**
* **Greedy answer:** "Acoustical" (displayed in red text)
* **Answer 1:** "Acoustical Engineering"
* **Answer 2:** "Acoustiics"
### Detailed Analysis
**Table Data Reconstruction:**
The following table lists the exact numerical values for each answer across all metrics.
| Answer | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
|---------------|---------|----------|----------|---------|---------|------|------|------|------|-----------|
| **Ref answer** | 1 | 0.45 | 0.96 | 0.86 | 0.88 | 0.64 | 0.73 | 0.93 | | |
| **Greedy answer** | 0 | 0.41 | 0.95 | 0.79 | 0.84 | 0.50 | 0.51 | 0.29 | 0.28 | 1 |
| **Answer 1** | 0 | 0.28 | 0.94 | 0.79 | 0.83 | 0.39 | 0.44 | 0.33 | | |
| **Answer 2** | 0 | 0.04 | 0.86 | 0.69 | 0.80 | 0.16 | 0.25 | 0.39 | | |
**Note on Empty Cells:** The cells for "SU" and "Ask4-conf" are empty for "Ref answer", "Answer 1", and "Answer 2". Only the "Greedy answer" has values in these columns.
### Key Observations
1. **Reference Answer Superiority:** The "Ref answer" ("Acoustics") scores a perfect 1.0 on Rouge-1, indicating an exact lexical match with the expected answer. It also has the highest scores in Max Ent (0.86), Avg Ent (0.88), Gb-S (0.64), Wb-S (0.73), and Bb-S (0.93).
2. **Greedy Answer Characteristics:** The "Greedy answer" ("Acoustical") has a Rouge-1 score of 0, meaning it does not match the reference word. It is the only answer with values for "SU" (0.28) and "Ask4-conf" (1). Its scores are generally lower than the reference answer but higher than the other alternatives in most probability and entropy metrics.
3. **Performance of Other Answers:** "Answer 1" and "Answer 2" have Rouge-1 scores of 0. "Answer 2" ("Acoustiics") has notably low scores, particularly in Max Prob (0.04) and Gb-S (0.16), suggesting the model assigns it very low probability and confidence.
4. **Metric Trends:** Across all answers, the "Avg Prob" (Average Probability) metric remains relatively high (0.86 to 0.96), while metrics like "Gb-S", "Wb-S", and "Bb-S" show greater variance, effectively differentiating the quality of the answers.
### Interpretation
This figure illustrates a method for evaluating and comparing the quality of different text generations from a language model. The data suggests that the model (Gemma-7B) can internally distinguish the correct reference answer ("Acoustics") from incorrect or less precise alternatives ("Acoustical", "Acoustical Engineering", "Acoustiics").
The **key takeaway** is that while the model's "greedy" decoding (which selects the single most probable next token) produced a suboptimal answer ("Acoustical"), the underlying probability and entropy metrics (Max Prob, Avg Ent, etc.) assigned higher values to the true reference answer. This discrepancy highlights a potential limitation of simple greedy decoding and supports the use of more sophisticated decoding strategies or scoring metrics (like those in the table) to identify the best response from a set of candidates. The "Ask4-conf" value of 1 for the greedy answer might indicate a specific confidence query or flag associated with that generation path. The empty cells for other answers in the last two columns suggest those metrics were not computed or are not applicable to them in this evaluation framework.