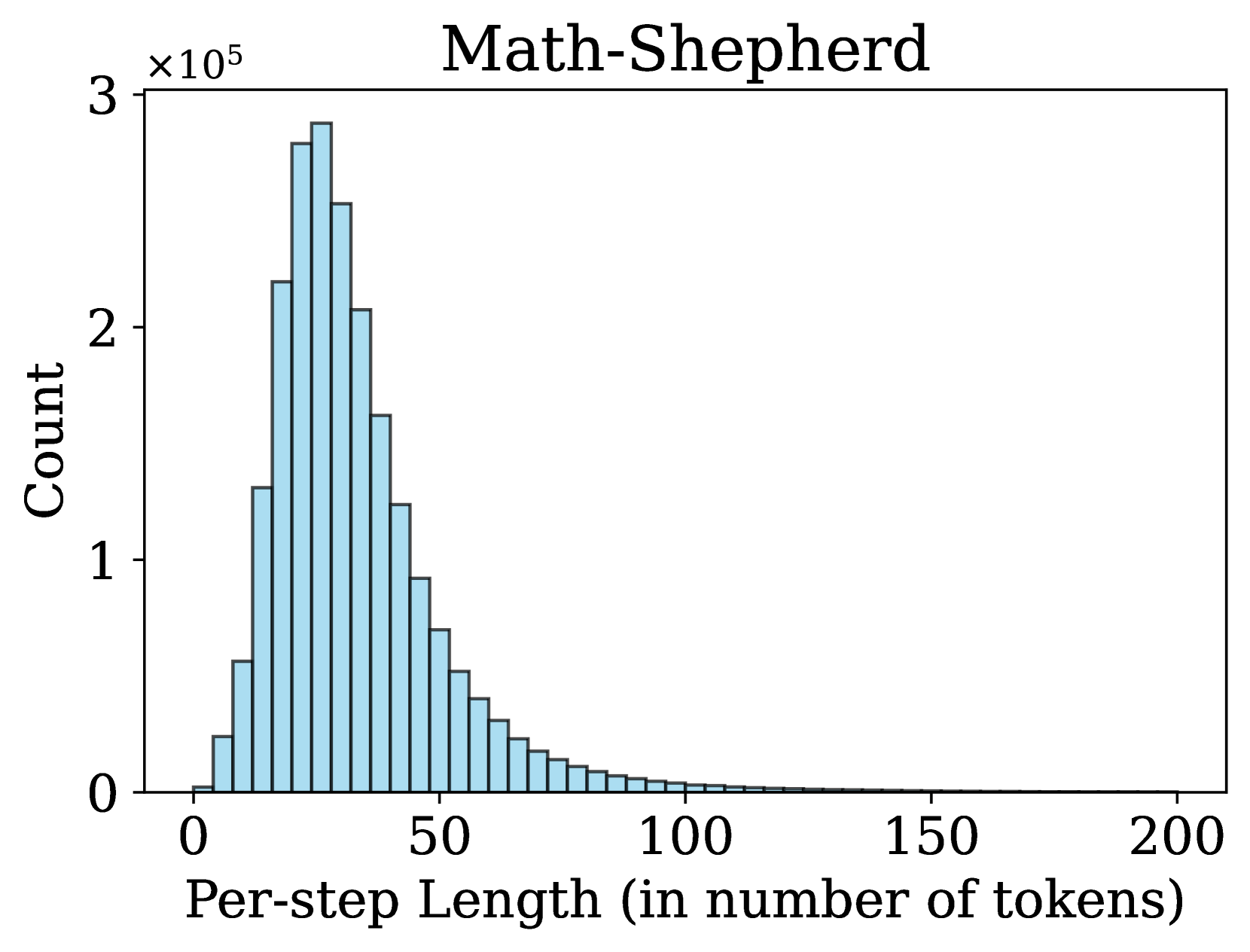
## Histogram: Math-Shepherd Per-Step Length Distribution
### Overview
The image displays a histogram titled "Math-Shepherd" showing the distribution of per-step lengths (in number of tokens) for a dataset. The y-axis represents counts scaled by 10⁵, and the x-axis ranges from 0 to 200 tokens. The distribution is right-skewed, with the highest frequency occurring at shorter per-step lengths.
### Components/Axes
- **Title**: "Math-Shepherd" (top-center, black text).
- **X-axis**:
- Label: "Per-step Length (in number of tokens)" (bottom, black text).
- Scale: 0 to 200, with major ticks at 0, 50, 100, 150, 200.
- **Y-axis**:
- Label: "Count" (left, black text).
- Scale: 0 to 3×10⁵, with increments of 1×10⁵.
- **Bars**:
- Color: Light blue (uniform across all bars).
- Positioning: Centered on x-axis bins (e.g., 0–10, 10–20, etc.).
### Detailed Analysis
- **Bars**:
- **0–10 tokens**: Count ≈ 2×10⁴ (lowest visible bar).
- **10–20 tokens**: Count ≈ 5×10⁴.
- **20–30 tokens**: Count ≈ 1.2×10⁵.
- **30–40 tokens**: Count ≈ 2.5×10⁵ (peak).
- **40–50 tokens**: Count ≈ 1.8×10⁵.
- **50–60 tokens**: Count ≈ 1.2×10⁵.
- **60–70 tokens**: Count ≈ 7×10⁴.
- **70–80 tokens**: Count ≈ 4×10⁴.
- **80–90 tokens**: Count ≈ 2×10⁴.
- **90–100 tokens**: Count ≈ 1×10⁴.
- **100–150 tokens**: Counts drop below 1×10³, becoming negligible.
- **150–200 tokens**: No visible bars (count ≈ 0).
### Key Observations
1. **Peak Frequency**: The highest count (~2.5×10⁵) occurs for per-step lengths of **30–40 tokens**.
2. **Rapid Decline**: Counts decrease by ~50% every 10 tokens after the peak (e.g., 1.8×10⁵ at 40–50 tokens, 1.2×10⁵ at 50–60 tokens).
3. **Long-Tail Behavior**: Fewer steps exceed 100 tokens, with counts dropping to near-zero beyond 150 tokens.
4. **Right-Skewed Distribution**: Most data points cluster at shorter per-step lengths, with a long tail toward larger values.
### Interpretation
The histogram suggests that in the Math-Shepherd context, **most computational steps involve 30–40 tokens**, with shorter steps being less frequent and longer steps extremely rare. The right-skewed distribution implies that while the majority of steps are concise, a small fraction of steps require significantly more tokens. This could reflect efficiency in typical problem-solving workflows, with occasional complex steps (e.g., multi-stage reasoning) accounting for outliers. The negligible counts beyond 150 tokens indicate that extremely long steps are either non-existent or exceedingly uncommon in this dataset.