\n
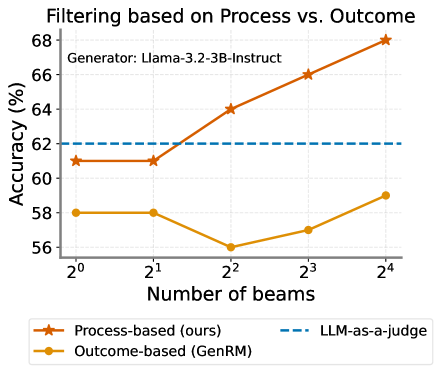
## Line Chart: Filtering based on Process vs. Outcome
### Overview
This line chart compares the accuracy of two filtering methods – process-based (labeled "ours") and outcome-based (GenRM) – as a function of the number of beams used. A baseline accuracy score from an LLM-as-a-judge is also presented for comparison. The generator used is Llama-3.2-3B-Instruct.
### Components/Axes
* **Title:** Filtering based on Process vs. Outcome
* **Subtitle:** Generator: Llama-3.2-3B-Instruct
* **X-axis:** Number of beams. Markers are at 2⁰, 2¹, 2², 2³, and 2⁴.
* **Y-axis:** Accuracy (%) with a scale ranging from approximately 56% to 68%.
* **Legend:**
* Process-based (ours) - Solid orange line with star markers.
* Outcome-based (GenRM) - Solid yellow line with star markers.
* LLM-as-a-judge - Dashed blue line.
### Detailed Analysis
* **Process-based (ours):** The orange line shows an upward trend.
* At 2⁰ (1 beam): Approximately 62% accuracy.
* At 2¹ (2 beams): Approximately 63% accuracy.
* At 2² (4 beams): Approximately 64% accuracy.
* At 2³ (8 beams): Approximately 66% accuracy.
* At 2⁴ (16 beams): Approximately 68% accuracy.
* **Outcome-based (GenRM):** The yellow line shows a downward trend initially, then a slight increase.
* At 2⁰ (1 beam): Approximately 61% accuracy.
* At 2¹ (2 beams): Approximately 58% accuracy.
* At 2² (4 beams): Approximately 56% accuracy.
* At 2³ (8 beams): Approximately 57% accuracy.
* At 2⁴ (16 beams): Approximately 59% accuracy.
* **LLM-as-a-judge:** The blue dashed line is approximately horizontal, indicating a relatively constant accuracy.
* Accuracy is consistently around 62%.
### Key Observations
* The process-based filtering method consistently outperforms the outcome-based method across all beam numbers.
* The process-based method shows a clear positive correlation between the number of beams and accuracy. Increasing the number of beams leads to improved accuracy.
* The outcome-based method initially decreases in accuracy as the number of beams increases, then shows a slight recovery.
* The LLM-as-a-judge provides a stable baseline for comparison.
### Interpretation
The data suggests that filtering based on the *process* of generation (the "ours" method) is more effective than filtering based on the *outcome* (GenRM) when using the Llama-3.2-3B-Instruct generator. The increasing accuracy of the process-based method with more beams indicates that a more thorough evaluation of the generation process leads to better results. The relatively flat line for the LLM-as-a-judge suggests that its accuracy doesn't significantly change with the number of beams, implying it's a consistent but potentially less sensitive metric. The initial drop in accuracy for the outcome-based method could indicate that simply evaluating the final output is less reliable, and may be susceptible to noise or superficial characteristics. The slight recovery at higher beam numbers might suggest that with more samples, the outcome-based method can identify some improvements, but it still doesn't reach the performance of the process-based approach. This implies that understanding *how* a model generates text is more valuable than simply assessing *what* it generates.