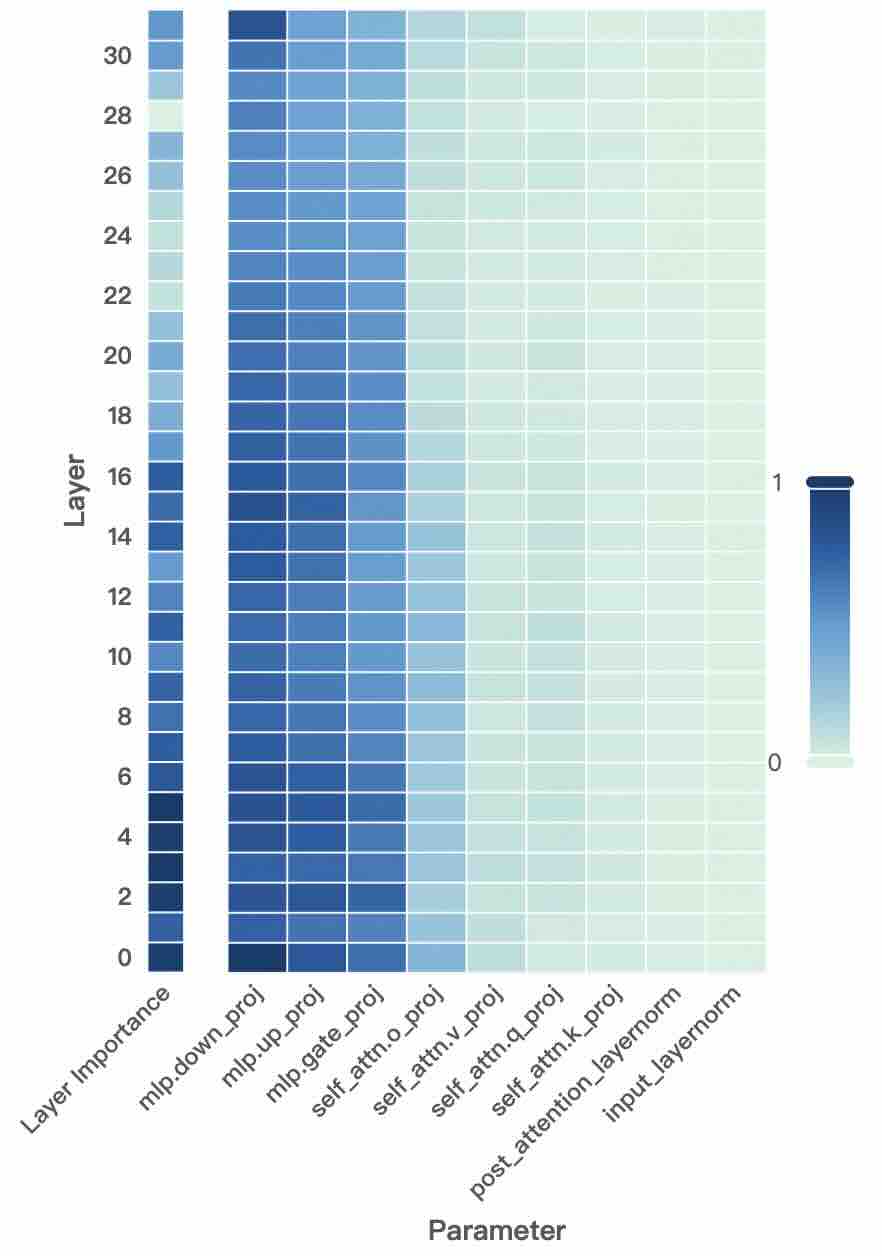
## Heatmap: Layer Importance vs. Parameter
### Overview
The image is a heatmap visualizing the importance of different layers (y-axis) for various parameters (x-axis) in a neural network. The color intensity represents the degree of importance, with darker blue indicating higher importance and lighter shades indicating lower importance.
### Components/Axes
* **Y-axis:** "Layer" with numerical scale from 2 to 30 in increments of 2.
* **X-axis:** "Parameter" with the following categories:
* Layer Importance
* mlp.down\_proj
* mlp.up\_proj
* mlp.gate\_proj
* self\_attn.o\_proj
* self\_attn.v\_proj
* self\_attn.q\_proj
* self\_attn.k\_proj
* post\_attention\_layernorm
* input\_layernorm
* **Color Legend:** Located on the right side of the heatmap, ranging from dark blue (representing a value of 1) to light green/white (representing a value of 0).
### Detailed Analysis
The heatmap shows the importance of each layer for each parameter.
* **Layer Importance:** The "Layer Importance" parameter shows high importance (dark blue) across all layers, from layer 2 to layer 30.
* **mlp.down\_proj, mlp.up\_proj, mlp.gate\_proj:** These parameters also show high importance (dark blue) across all layers.
* **self\_attn.o\_proj:** This parameter shows high importance (dark blue) from layer 2 to approximately layer 16, then gradually decreases in importance (lighter shades of blue) towards layer 30.
* **self\_attn.v\_proj, self\_attn.q\_proj, self\_attn.k\_proj:** These parameters show a similar trend to "self\_attn.o\_proj," with high importance in lower layers and decreasing importance in higher layers, transitioning to light blue/green.
* **post\_attention\_layernorm, input\_layernorm:** These parameters show low importance (light green/white) across all layers.
### Key Observations
* The "Layer Importance," "mlp.down\_proj," "mlp.up\_proj," and "mlp.gate\_proj" parameters are consistently important across all layers.
* The importance of "self\_attn.o\_proj," "self\_attn.v\_proj," "self\_attn.q\_proj," and "self\_attn.k\_proj" parameters decreases as the layer number increases.
* The "post\_attention\_layernorm" and "input\_layernorm" parameters have low importance across all layers.
### Interpretation
The heatmap suggests that certain parameters (Layer Importance, mlp.down\_proj, mlp.up\_proj, mlp.gate\_proj) are crucial for all layers of the neural network. Self-attention related parameters (self\_attn.o\_proj, self\_attn.v\_proj, self\_attn.q\_proj, self\_attn.k\_proj) are more important in the lower layers, possibly indicating that these layers are responsible for capturing initial contextual information. The layernorm parameters (post\_attention\_layernorm, input\_layernorm) appear to have a less significant role in the network's performance, at least according to this importance metric. The data demonstrates a clear distinction in the importance of different parameters across the layers of the neural network.