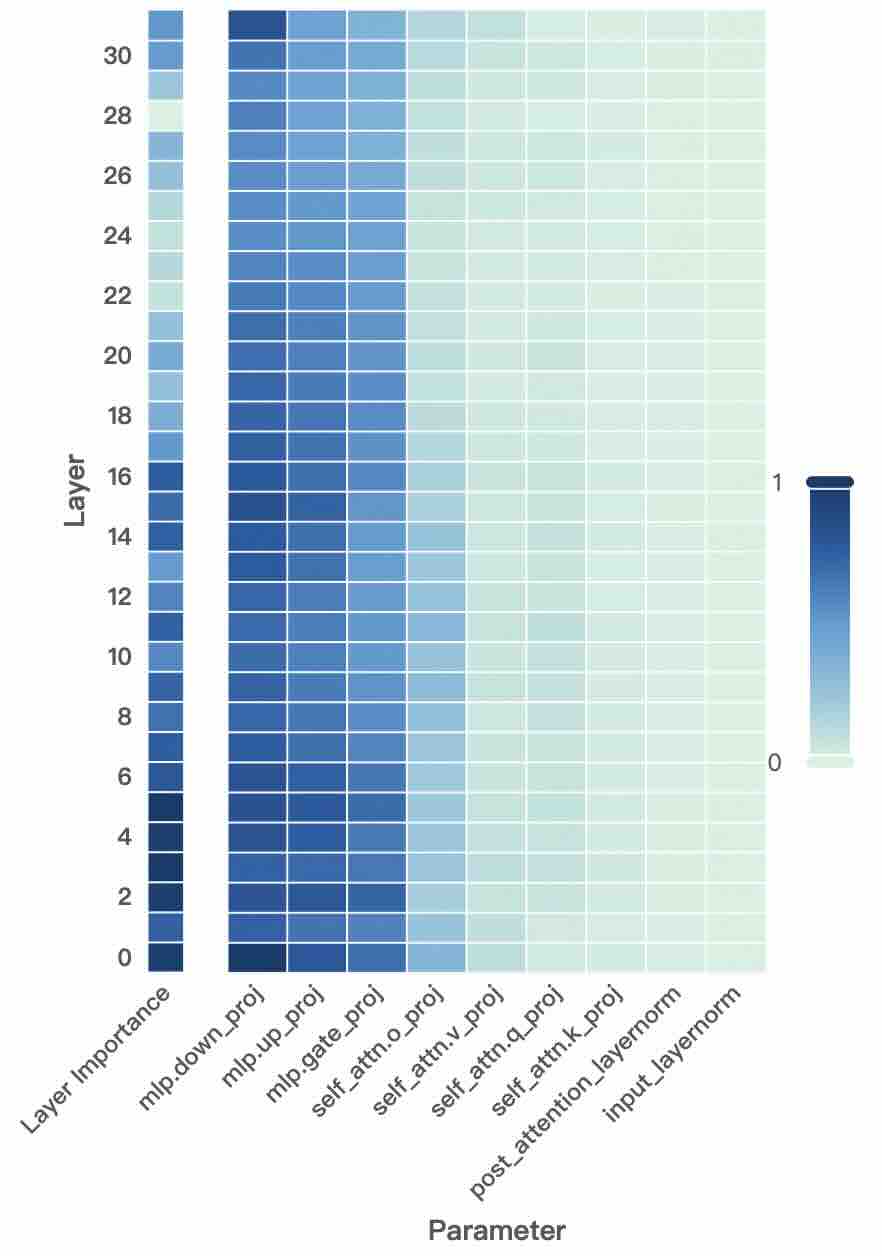
## Heatmap: Layer Importance vs. Parameter
### Overview
This image presents a heatmap visualizing the relationship between layer number and the importance assigned to different parameters within a neural network model. The heatmap uses a color gradient to represent the magnitude of layer importance, ranging from 0 (lightest color) to 1 (darkest color).
### Components/Axes
* **X-axis:** "Parameter" - Categorical variable representing different parameters within the model. The parameters are: `mlp.down_proj`, `mlp.up_proj`, `mlp.gate_proj`, `self_attn.o_proj`, `self_attn.v_proj`, `self_attn.q_proj`, `self_attn.k_proj`, `post_attention_layernorm`, `input_layernorm`.
* **Y-axis:** "Layer" - Numerical variable representing the layer number, ranging from 0 to 30.
* **Color Scale/Legend:** A vertical color bar on the right side of the heatmap. It maps color intensity to the value of layer importance.
* 0 is represented by a light cyan color.
* 1 is represented by a dark blue color.
* Intermediate values are represented by shades of blue.
### Detailed Analysis
The heatmap displays the layer importance for each parameter across different layers. The color intensity indicates the degree of importance.
* **mlp.down_proj:** Shows high importance (dark blue) for layers 0-16, then rapidly decreases to near zero for layers 17-30.
* **mlp.up_proj:** Similar to `mlp.down_proj`, high importance for layers 0-16, decreasing to near zero for layers 17-30.
* **mlp.gate_proj:** High importance for layers 0-16, decreasing to near zero for layers 17-30.
* **self_attn.o_proj:** Shows a moderate level of importance (medium blue) for layers 0-24, then decreases to near zero for layers 25-30.
* **self_attn.v_proj:** Shows a moderate level of importance (medium blue) for layers 0-24, then decreases to near zero for layers 25-30.
* **self_attn.q_proj:** Shows a moderate level of importance (medium blue) for layers 0-24, then decreases to near zero for layers 25-30.
* **self_attn.k_proj:** Shows a moderate level of importance (medium blue) for layers 0-24, then decreases to near zero for layers 25-30.
* **post_attention_layernorm:** Shows a low level of importance (light blue) across all layers, with a slight increase in layers 10-20.
* **input_layernorm:** Shows a very low level of importance (almost white) across all layers.
**Approximate Data Points (based on visual inspection):**
| Parameter | Layer 0 | Layer 8 | Layer 16 | Layer 24 | Layer 30 |
| ----------------------- | ------- | ------- | -------- | -------- | -------- |
| mlp.down_proj | ~1.0 | ~1.0 | ~1.0 | ~0.2 | ~0.0 |
| mlp.up_proj | ~1.0 | ~1.0 | ~1.0 | ~0.2 | ~0.0 |
| mlp.gate_proj | ~1.0 | ~1.0 | ~1.0 | ~0.2 | ~0.0 |
| self_attn.o_proj | ~0.8 | ~0.8 | ~0.6 | ~0.4 | ~0.0 |
| self_attn.v_proj | ~0.8 | ~0.8 | ~0.6 | ~0.4 | ~0.0 |
| self_attn.q_proj | ~0.8 | ~0.8 | ~0.6 | ~0.4 | ~0.0 |
| self_attn.k_proj | ~0.8 | ~0.8 | ~0.6 | ~0.4 | ~0.0 |
| post_attention_layernorm| ~0.1 | ~0.2 | ~0.2 | ~0.1 | ~0.0 |
| input_layernorm | ~0.0 | ~0.0 | ~0.0 | ~0.0 | ~0.0 |
### Key Observations
* The `mlp` parameters (`mlp.down_proj`, `mlp.up_proj`, `mlp.gate_proj`) exhibit significantly higher importance in the initial layers (0-16) and then rapidly diminish in deeper layers.
* The `self_attn` parameters (`self_attn.o_proj`, `self_attn.v_proj`, `self_attn.q_proj`, `self_attn.k_proj`) show moderate importance in the initial to mid layers (0-24) and then decrease.
* `post_attention_layernorm` has consistently low importance across all layers.
* `input_layernorm` has negligible importance across all layers.
* There is a clear trend of decreasing importance for most parameters as the layer number increases.
### Interpretation
This heatmap suggests that the initial layers of the model (0-16) heavily rely on the `mlp` parameters for processing information. As the information propagates through deeper layers, the importance of these `mlp` parameters decreases, while the `self_attn` parameters play a more significant role in the mid-layers (up to layer 24). The consistently low importance of `post_attention_layernorm` and `input_layernorm` indicates that these parameters have a limited impact on the overall model performance.
The observed trend of decreasing importance with increasing layer number could indicate that the model is learning to extract increasingly abstract features in the deeper layers, requiring less reliance on the initial parameter transformations. This is a common pattern in deep learning models, where lower layers learn basic features and higher layers combine these features to form more complex representations. The rapid drop-off in importance for the `mlp` parameters after layer 16 might suggest a transition in the model's processing strategy, potentially relying more on attention mechanisms in the deeper layers.