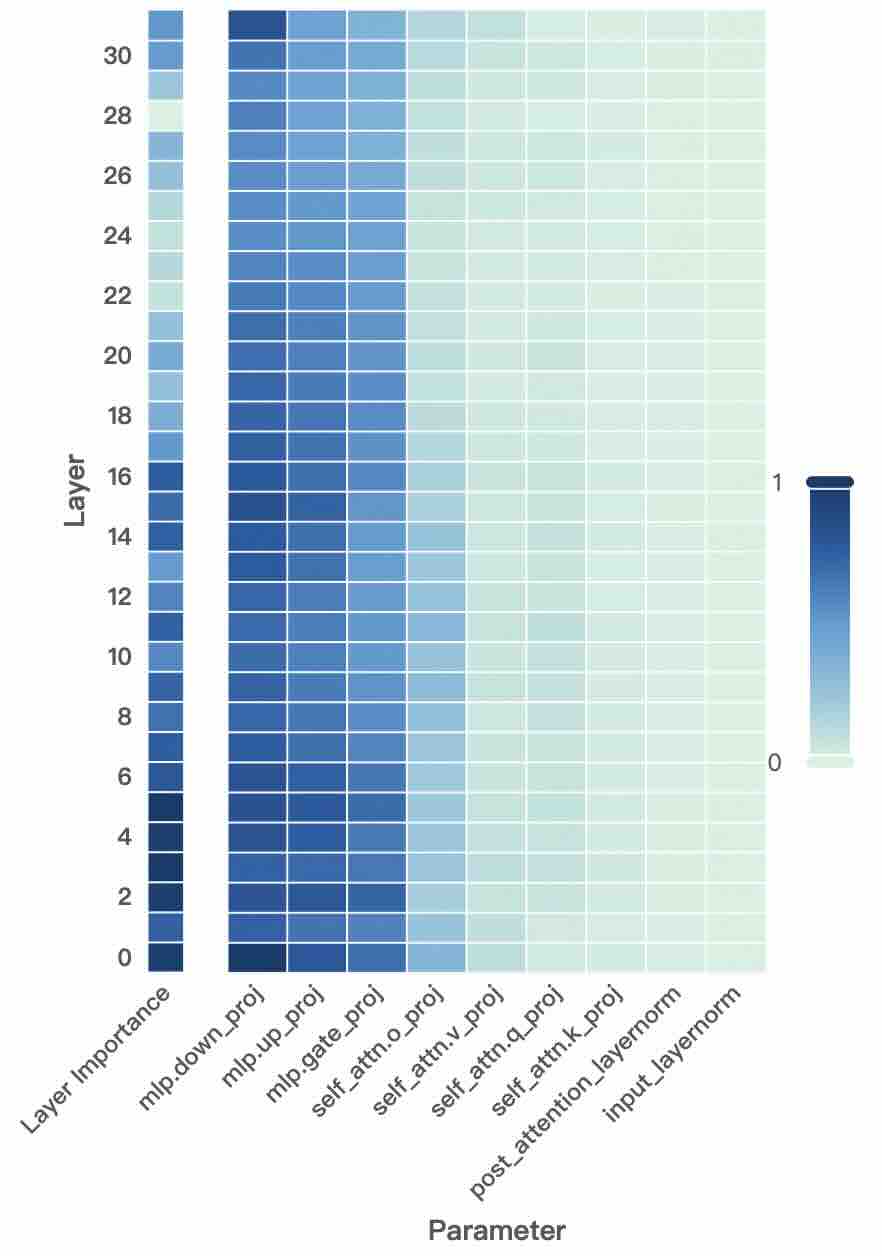
## Heatmap: Parameter Importance Across Transformer Layers
### Overview
The image is a heatmap visualizing the importance of various parameters across 31 transformer layers (0–30). Darker blue shades indicate higher importance (closer to 1), while lighter shades represent lower importance (closer to 0). The x-axis lists parameters, and the y-axis represents layers. The colorbar on the right quantifies importance from 0 to 1.
### Components/Axes
- **X-axis (Parameters)**:
- `Layer Importance`
- `mlp.down_proj`
- `mlp.up_proj`
- `mlp.gate_proj`
- `mlp.attn.o_proj`
- `self_attn.v_proj`
- `self_attn.q_proj`
- `self_attn.k_proj`
- `post_attention_layernorm`
- `input_layernorm`
- **Y-axis (Layers)**:
- Layers labeled from 0 (bottom) to 30 (top).
- **Color Legend**:
- Dark blue = 1 (highest importance)
- Light gray = 0 (lowest importance)
### Detailed Analysis
- **Layer Importance**:
- Peaks in **layers 0–2** (darkest blue), then gradually lightens toward layer 30.
- Approximate values: ~0.9 (layer 0), ~0.7 (layer 10), ~0.3 (layer 30).
- **MLP Projections**:
- `mlp.down_proj` and `mlp.up_proj` show strong importance in **layers 0–10** (~0.8–0.6), fading to ~0.2 in higher layers.
- `mlp.gate_proj` is consistently dark in **layers 0–15** (~0.7–0.5), then lightens.
- **Self-Attention Projections**:
- `self_attn.v_proj` and `self_attn.q_proj` have moderate importance in **layers 5–20** (~0.5–0.4), with peaks around layer 10.
- `self_attn.k_proj` follows a similar trend but is slightly lighter (~0.4–0.3).
- **Layer Normalization**:
- `post_attention_layernorm` and `input_layernorm` are uniformly light across all layers (~0.1–0.2), indicating minimal importance.
### Key Observations
1. **Layer-Specific Importance**:
- Lower layers (0–10) dominate in parameter importance, with values dropping sharply after layer 20.
- `Layer Importance` and MLP projections (`mlp.down_proj`, `mlp.up_proj`) are most critical in early layers.
2. **Self-Attention Patterns**:
- Self-attention projections (`v_proj`, `q_proj`, `k_proj`) show moderate importance in mid-layers (5–20), suggesting their role in intermediate processing.
3. **Normalization Insignificance**:
- Both `post_attention_layernorm` and `input_layernorm` are consistently light, implying minimal impact on model behavior.
### Interpretation
The heatmap reveals that **early layers** (0–10) are critical for parameter-driven transformations, particularly MLP and self-attention projections. The sharp decline in importance after layer 20 suggests that higher layers may focus on higher-level abstractions or rely on precomputed features. The negligible importance of layer normalization parameters across all layers indicates that these components may not significantly influence the model’s output in this context. This pattern aligns with typical transformer architectures, where lower layers handle feature extraction and higher layers refine representations.
**Notable Outlier**: `mlp.gate_proj` maintains moderate importance up to layer 15, suggesting a prolonged role in gating mechanisms compared to other MLP projections.