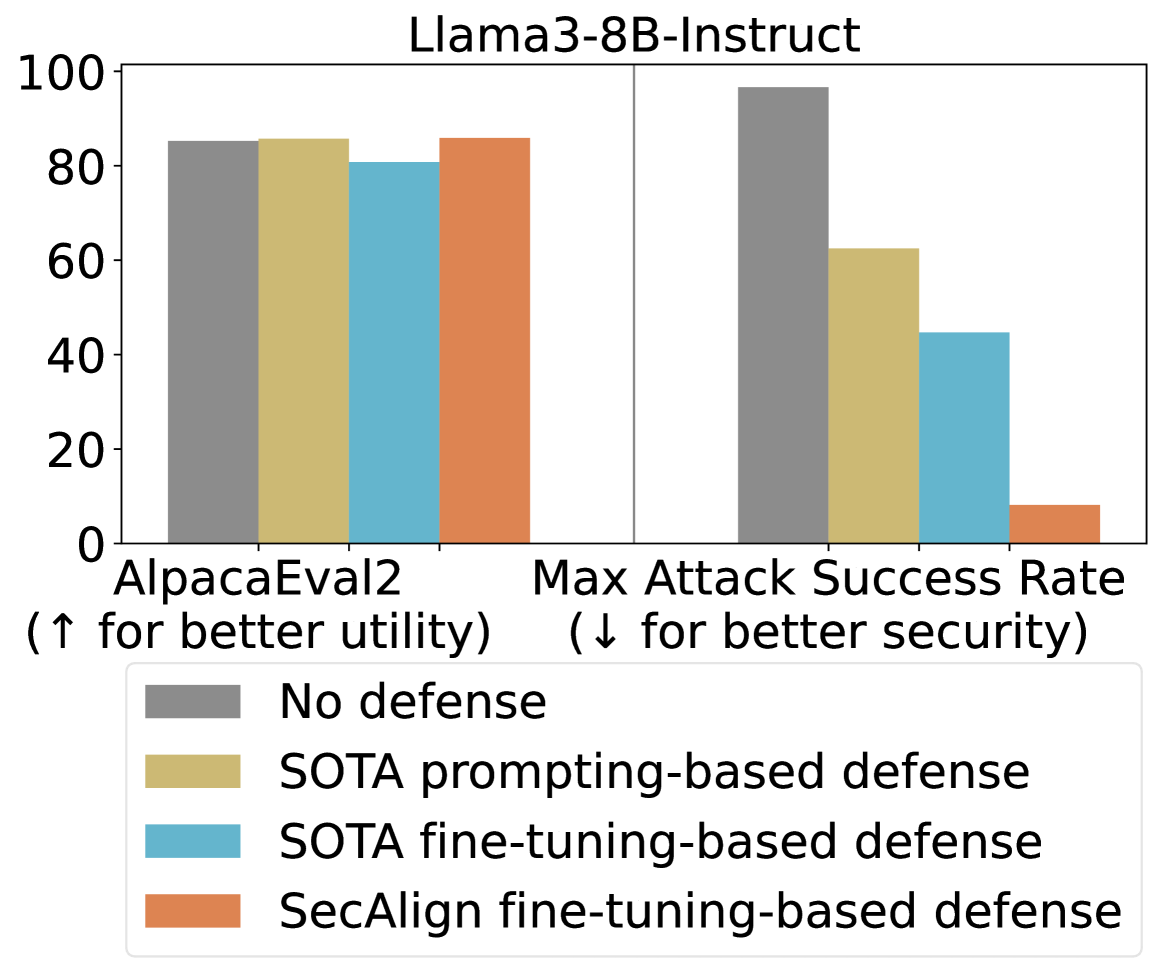
## Bar Chart: Llama3-8B-Instruct Performance with Different Defenses
### Overview
The chart compares the performance of Llama3-8B-Instruct under different defense mechanisms across two metrics: **AlpacaEval2** (utility) and **Max Attack Success Rate** (security). Four defense strategies are evaluated: No defense, SOTA prompting-based defense, SOTA fine-tuning-based defense, and SecAlign fine-tuning-based defense. Utility is measured with ↑ (higher = better), while security uses ↓ (lower = better).
### Components/Axes
- **X-axis**:
- Categories: "AlpacaEval2" (utility) and "Max Attack Success Rate" (security).
- Labels: "AlpacaEval2" and "Max Attack Success Rate".
- **Y-axis**:
- Scale: 0 to 100 (percentage).
- Labels: Numerical values with ↑ (utility) and ↓ (security) annotations.
- **Legend**:
- Position: Bottom-left.
- Entries:
- Gray: No defense
- Beige: SOTA prompting-based defense
- Blue: SOTA fine-tuning-based defense
- Orange: SecAlign fine-tuning-based defense
### Detailed Analysis
#### AlpacaEval2 (Utility)
- **No defense (gray)**: ~85
- **SOTA prompting (beige)**: ~86
- **SOTA fine-tuning (blue)**: ~82
- **SecAlign fine-tuning (orange)**: ~87
*Trend*: All defenses perform similarly, with SecAlign fine-tuning slightly outperforming others.
#### Max Attack Success Rate (Security)
- **No defense (gray)**: ~98
- **SOTA prompting (beige)**: ~63
- **SOTA fine-tuning (blue)**: ~45
- **SecAlign fine-tuning (orange)**: ~8
*Trend*: Defenses significantly reduce attack success rates. SecAlign fine-tuning achieves the lowest success rate (~8), while SOTA prompting reduces it to ~63.
### Key Observations
1. **Utility vs. Security Trade-off**:
- Defenses minimally impact utility (AlpacaEval2: 82–87) but drastically improve security (Max Attack Success Rate: 8–98).
2. **SecAlign Superiority**:
- SecAlign fine-tuning achieves the highest utility (~87) and lowest attack success rate (~8), outperforming other defenses.
3. **No Defense Baseline**:
- No defense has the highest attack success rate (~98), highlighting vulnerability without protection.
### Interpretation
The data demonstrates that defense mechanisms effectively balance utility and security. While all defenses maintain high utility (near baseline), SecAlign fine-tuning excels in security, reducing attack success rates by ~90% compared to no defense. This suggests SecAlign is optimal for high-security applications, whereas SOTA prompting offers moderate security with minimal utility loss. The chart underscores the importance of fine-tuning defenses for critical security requirements.