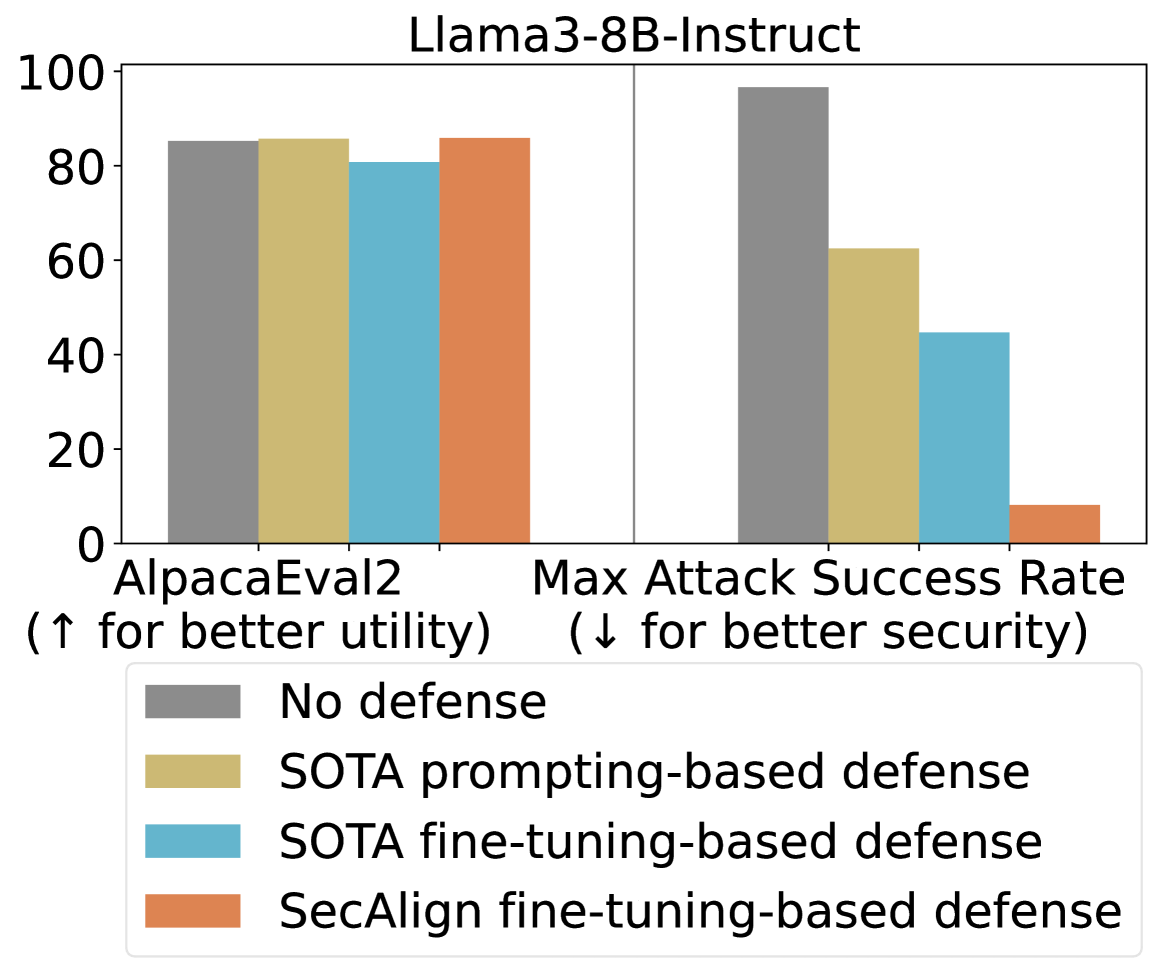
## Bar Chart: Llama3-8B-Instruct Performance
### Overview
The image is a bar chart comparing the performance of the Llama3-8B-Instruct model under different defense mechanisms. It shows the model's performance on AlpacaEval2 (utility) and Max Attack Success Rate (security). The chart compares the model with no defense, SOTA prompting-based defense, SOTA fine-tuning-based defense, and SecAlign fine-tuning-based defense.
### Components/Axes
* **Title:** Llama3-8B-Instruct
* **Y-axis:** Numerical scale from 0 to 100, incrementing by 20.
* **X-axis:** Two categories:
* AlpacaEval2 (↑ for better utility)
* Max Attack Success Rate (↓ for better security)
* **Legend:** Located at the bottom of the chart.
* Gray: No defense
* Tan: SOTA prompting-based defense
* Blue: SOTA fine-tuning-based defense
* Orange: SecAlign fine-tuning-based defense
### Detailed Analysis
**AlpacaEval2 (Utility):**
* **No defense (Gray):** Approximately 86
* **SOTA prompting-based defense (Tan):** Approximately 87
* **SOTA fine-tuning-based defense (Blue):** Approximately 81
* **SecAlign fine-tuning-based defense (Orange):** Approximately 87
**Max Attack Success Rate (Security):**
* **No defense (Gray):** Approximately 97
* **SOTA prompting-based defense (Tan):** Approximately 62
* **SOTA fine-tuning-based defense (Blue):** Approximately 45
* **SecAlign fine-tuning-based defense (Orange):** Approximately 8
### Key Observations
* For AlpacaEval2, all defense mechanisms show similar performance, with SOTA prompting-based defense and SecAlign fine-tuning-based defense slightly outperforming the others.
* For Max Attack Success Rate, SecAlign fine-tuning-based defense significantly reduces the success rate compared to other methods.
* The "No defense" case has the highest attack success rate.
### Interpretation
The chart suggests that while SOTA prompting-based defense and SecAlign fine-tuning-based defense provide similar utility (as measured by AlpacaEval2), SecAlign fine-tuning-based defense offers a substantial improvement in security by significantly reducing the Max Attack Success Rate. This indicates that SecAlign fine-tuning is more effective in defending against attacks compared to the other methods tested. The "No defense" case serves as a baseline, highlighting the vulnerability of the model without any defense mechanisms.