\n
## Bar Chart: Correctness Percentage by Method
### Overview
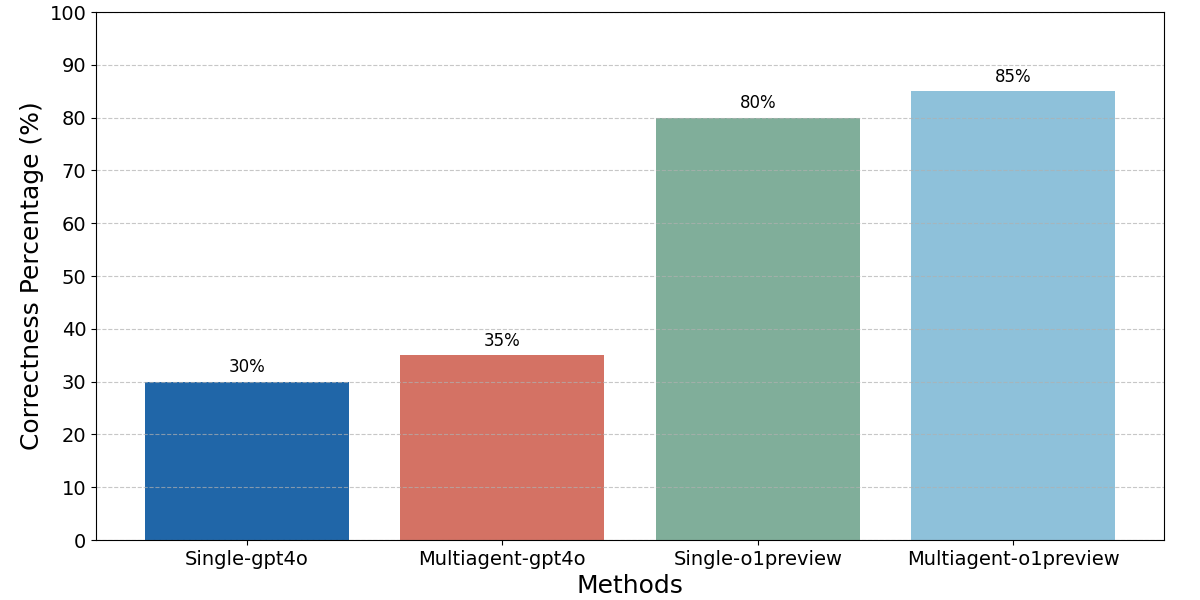
This bar chart compares the correctness percentage achieved by four different methods: Single-gpt4o, Multiagent-gpt4o, Single-o1preview, and Multiagent-o1preview. The y-axis represents the correctness percentage, ranging from 0% to 100%, while the x-axis represents the different methods being compared. Each method is represented by a distinct colored bar, with the height of the bar indicating the corresponding correctness percentage.
### Components/Axes
* **X-axis Label:** Methods
* **Y-axis Label:** Correctness Percentage (%)
* **X-axis Categories:** Single-gpt4o, Multiagent-gpt4o, Single-o1preview, Multiagent-o1preview
* **Y-axis Scale:** 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100
* **Bar Colors:**
* Single-gpt4o: Blue
* Multiagent-gpt4o: Red
* Single-o1preview: Green
* Multiagent-o1preview: Teal
### Detailed Analysis
* **Single-gpt4o:** The blue bar for Single-gpt4o reaches approximately 30% on the y-axis.
* **Multiagent-gpt4o:** The red bar for Multiagent-gpt4o reaches approximately 35% on the y-axis.
* **Single-o1preview:** The green bar for Single-o1preview reaches approximately 80% on the y-axis.
* **Multiagent-o1preview:** The teal bar for Multiagent-o1preview reaches approximately 85% on the y-axis.
The bars representing Single-o1preview and Multiagent-o1preview are significantly taller than those representing Single-gpt4o and Multiagent-gpt4o, indicating a much higher correctness percentage.
### Key Observations
* The methods utilizing "o1preview" (Single-o1preview and Multiagent-o1preview) demonstrate substantially higher correctness percentages compared to those using "gpt4o" (Single-gpt4o and Multiagent-gpt4o).
* Multiagent-o1preview has the highest correctness percentage at approximately 85%.
* Single-gpt4o has the lowest correctness percentage at approximately 30%.
* The difference in correctness percentage between Single-gpt4o and Multiagent-gpt4o is relatively small (5%).
* The difference in correctness percentage between Single-o1preview and Multiagent-o1preview is also relatively small (5%).
### Interpretation
The data suggests that the "o1preview" methods are significantly more accurate than the "gpt4o" methods. This could be due to improvements in the underlying model or the specific implementation of the "o1preview" versions. The slight improvement observed when using a multi-agent approach with "o1preview" suggests that leveraging multiple agents can further enhance accuracy, but the effect is not substantial. The relatively low correctness percentages for the "gpt4o" methods indicate that they may require further refinement or are less suitable for the task being evaluated. The consistent 5% difference between single and multi-agent approaches within each model family suggests a systematic benefit to the multi-agent approach, but it is a modest improvement. This data could be used to inform decisions about which method to use for a given application, prioritizing the "o1preview" methods for tasks where accuracy is critical.