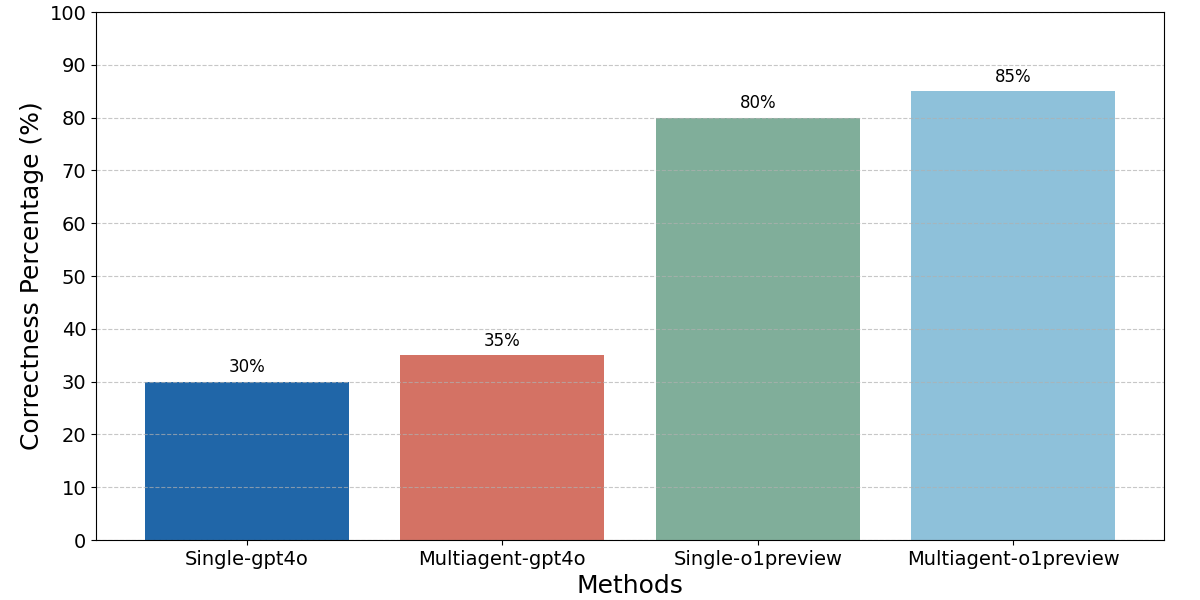
## Bar Chart: Comparison of Correctness Percentages by Method
### Overview
The image is a vertical bar chart comparing the "Correctness Percentage" achieved by four different methods. The chart clearly shows a performance hierarchy, with methods using the "o1preview" model significantly outperforming those using the "gpt4o" model.
### Components/Axes
* **X-Axis (Horizontal):** Labeled "Methods". It contains four categorical labels, each corresponding to a bar.
* **Categories (from left to right):**
1. `Single-gpt4o`
2. `Multiagent-gpt4o`
3. `Single-o1preview`
4. `Multiagent-o1preview`
* **Y-Axis (Vertical):** Labeled "Correctness Percentage (%)". The scale runs from 0 to 100 in increments of 10. Horizontal grid lines are present at each 10% increment.
* **Data Series & Legend:** There is no separate legend. Each bar is uniquely colored and directly labeled with its category name on the x-axis and its exact percentage value above the bar.
* **Bar 1 (Leftmost):** Color: Dark blue. Label: `Single-gpt4o`. Value: `30%`.
* **Bar 2:** Color: Terracotta/red-orange. Label: `Multiagent-gpt4o`. Value: `35%`.
* **Bar 3:** Color: Sage green. Label: `Single-o1preview`. Value: `80%`.
* **Bar 4 (Rightmost):** Color: Light sky blue. Label: `Multiagent-o1preview`. Value: `85%`.
### Detailed Analysis
The chart presents a direct comparison of four discrete data points.
1. **Single-gpt4o:** The leftmost bar, colored dark blue, reaches the 30% line on the y-axis. The text "30%" is centered above it.
2. **Multiagent-gpt4o:** The second bar, colored terracotta, is slightly taller than the first. It aligns with the midpoint between the 30% and 40% grid lines. The text "35%" is centered above it.
3. **Single-o1preview:** The third bar, colored sage green, shows a substantial increase in height. Its top aligns exactly with the 80% grid line. The text "80%" is centered above it.
4. **Multiagent-o1preview:** The rightmost and tallest bar, colored light sky blue, extends slightly above the 80% line. The text "85%" is centered above it.
**Trend Verification:** The visual trend is a clear, stepwise increase in bar height from left to right. The first two bars (gpt4o-based methods) are clustered in the lower third of the chart (30-35%). The last two bars (o1preview-based methods) are clustered in the upper fifth of the chart (80-85%). Within each model pair (gpt4o and o1preview), the "Multiagent" variant shows a modest 5 percentage point improvement over its "Single" counterpart.
### Key Observations
* **Performance Gap:** There is a dramatic performance gap of 45-50 percentage points between the methods using the "gpt4o" model and those using the "o1preview" model.
* **Consistent Multiagent Improvement:** For both underlying models (gpt4o and o1preview), the multiagent approach yields a consistent +5% correctness improvement over the single-agent approach.
* **Highest and Lowest:** The highest correctness is achieved by `Multiagent-o1preview` (85%), and the lowest by `Single-gpt4o` (30%).
* **Visual Grouping:** The chart's color scheme and spacing naturally group the two gpt4o methods together on the left and the two o1preview methods together on the right, emphasizing the model-based performance tier.
### Interpretation
This chart demonstrates two key findings regarding the evaluated methods:
1. **Model Capability is the Primary Driver:** The choice of underlying AI model ("o1preview" vs. "gpt4o") has a far greater impact on correctness performance than the architectural choice between single and multiagent systems. The "o1preview" model represents a generational leap in capability for this specific task, as evidenced by the ~50% absolute performance increase.
2. **Multiagent Systems Offer Reliable, Incremental Gains:** Regardless of the base model's power, structuring the system as a multiagent collaboration provides a consistent, measurable benefit (+5% correctness). This suggests that the multiagent framework adds robustness or error-correction capabilities that are complementary to the raw power of the individual model.
**Conclusion:** The data suggests that for maximizing correctness on this task, using the most capable base model ("o1preview") is essential. Implementing that model within a multiagent architecture then provides an additional, reliable performance boost. The results argue for investing in both advanced model development and sophisticated system architectures.