## Pie Charts: Error Analysis of Language Models
### Overview
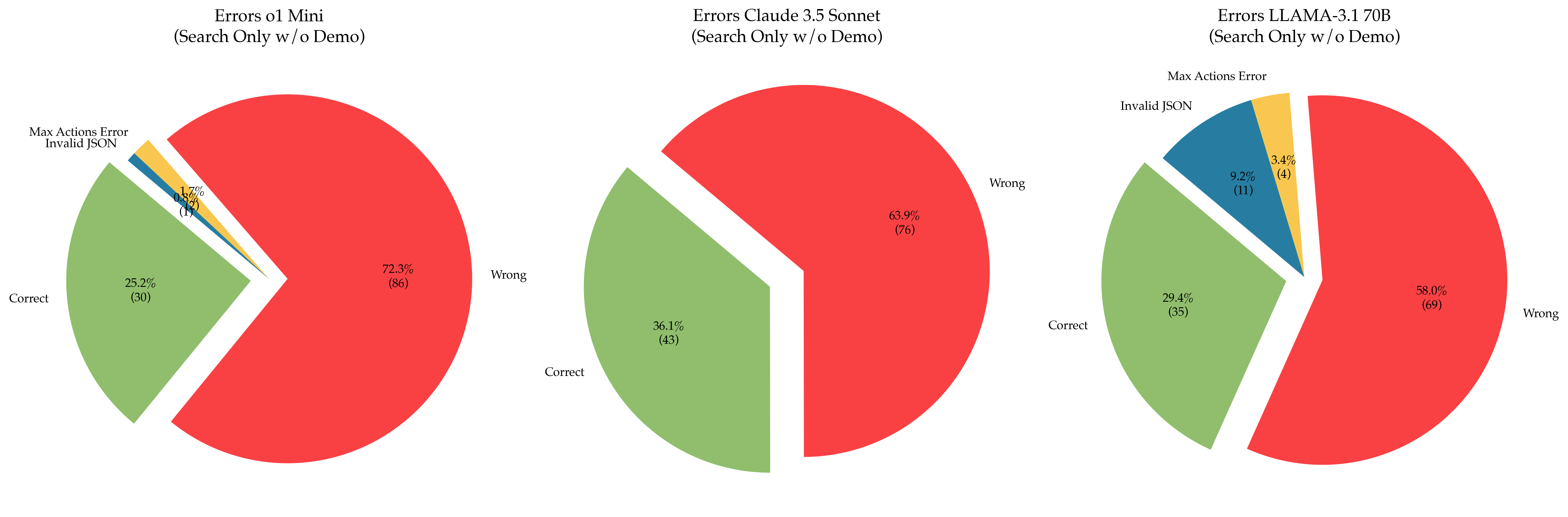
The image presents three pie charts comparing the error types of three language models: `ol Mini`, `Claude 3.5 Sonnet`, and `LLAMA-3.1 70B`. The charts represent the distribution of errors when the models are used for search-only tasks without a demo. The error categories are "Correct", "Wrong", "Invalid JSON", and "Max Actions Error". Each pie chart includes the percentage and count of each error type.
### Components/Axes
Each chart has the following components:
* **Title:** Indicates the model being analyzed and the search conditions.
* **Pie Segments:** Represent the proportion of each error type.
* **Labels:** Each segment is labeled with the error type and the percentage/count.
* **Color Coding:**
* Correct: Green
* Wrong: Red
* Invalid JSON: Light Blue
* Max Actions Error: Teal
### Detailed Analysis or Content Details
**1. ol Mini (Search Only w/o Demo)**
* **Correct:** 25.2% (30) - Green segment.
* **Wrong:** 72.9% (86) - Red segment.
* **Invalid JSON:** 1.7% (2) - Light Blue segment.
* **Max Actions Error:** 0.2% (0) - Teal segment.
**2. Claude 3.5 Sonnet (Search Only w/o Demo)**
* **Correct:** 36.1% (43) - Green segment.
* **Wrong:** 63.9% (76) - Red segment.
* **Invalid JSON:** Not present.
* **Max Actions Error:** Not present.
**3. LLAMA-3.1 70B (Search Only w/o Demo)**
* **Correct:** 29.4% (35) - Green segment.
* **Wrong:** 58.0% (69) - Red segment.
* **Invalid JSON:** 9.2% (11) - Light Blue segment.
* **Max Actions Error:** 3.4% (4) - Teal segment.
### Key Observations
* All three models have a majority of "Wrong" answers.
* `ol Mini` has the lowest percentage of correct answers (25.2%) and the highest percentage of wrong answers (72.9%).
* `Claude 3.5 Sonnet` has the highest percentage of correct answers (36.1%) but also a high percentage of wrong answers (63.9%).
* `LLAMA-3.1 70B` shows a more diverse error distribution, with significant percentages for "Wrong", "Invalid JSON", and "Max Actions Error".
* `ol Mini` is the only model that has a non-zero percentage of "Max Actions Error".
* `LLAMA-3.1 70B` is the only model that has a non-negligible percentage of "Invalid JSON" errors.
### Interpretation
The data suggests that all three language models struggle with accuracy in search-only tasks without a demo. The models are more likely to produce incorrect answers ("Wrong") than correct ones. The differences in error distribution between the models indicate varying strengths and weaknesses.
`ol Mini` appears to be the least reliable, with a high proportion of incorrect answers and a small number of errors related to JSON formatting or action limits. `Claude 3.5 Sonnet` performs better in terms of correctness but still has a substantial error rate. `LLAMA-3.1 70B` exhibits a more complex error profile, suggesting potential issues with JSON output and action handling in addition to general inaccuracy.
The presence of "Invalid JSON" and "Max Actions Error" in `LLAMA-3.1 70B` could indicate problems with the model's ability to generate well-formed JSON responses or to manage the number of actions it attempts to perform. The fact that `ol Mini` has a "Max Actions Error" suggests a similar limitation.
The absence of "Invalid JSON" and "Max Actions Error" in `Claude 3.5 Sonnet` might indicate a more robust output format or better action management capabilities. However, its high "Wrong" percentage suggests that the model's core reasoning or knowledge base may be flawed.
These findings highlight the importance of evaluating language models not only on overall accuracy but also on the types of errors they produce. Understanding the error distribution can help identify specific areas for improvement and guide the development of more reliable and robust language models.