## [Pie Charts]: Comparative Error Distributions for Three AI Models in Search-Only Tasks
### Overview
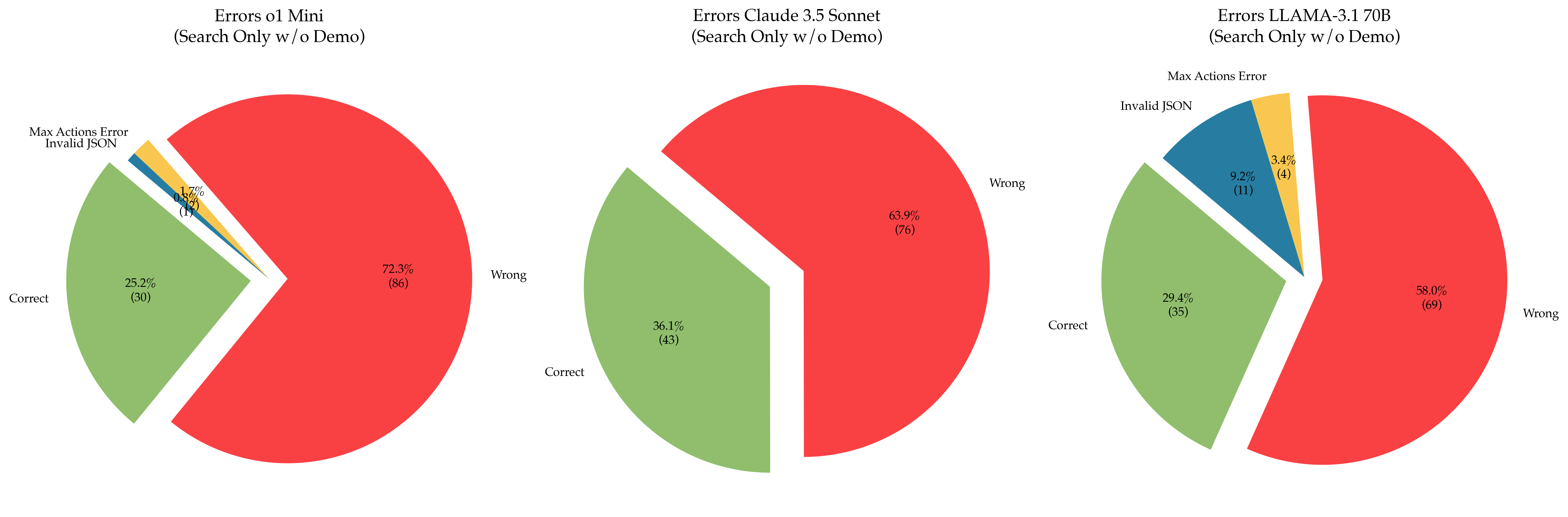
The image displays three horizontally arranged pie charts, each illustrating the distribution of outcomes (Correct, Wrong, and specific error types) for a different large language model (LLM) when performing a "Search Only" task without a demonstration ("w/o Demo"). The charts compare the performance of "o1 Mini", "Claude 3.5 Sonnet", and "LLAMA-3.1 70B".
### Components/Axes
* **Chart Titles (Top-Center of each chart):**
* Left Chart: `Errors o1 Mini (Search Only w/o Demo)`
* Center Chart: `Errors Claude 3.5 Sonnet (Search Only w/o Demo)`
* Right Chart: `Errors LLAMA-3.1 70B (Search Only w/o Demo)`
* **Legend / Segment Labels:** The labels are placed directly adjacent to their corresponding pie slices. The color coding is consistent across all charts:
* **Green Slice:** `Correct`
* **Red Slice:** `Wrong`
* **Blue Slice:** `Invalid JSON`
* **Yellow Slice:** `Max Actions Error`
* **Data Labels:** Each slice contains two lines of text: the percentage of the total and, in parentheses, the absolute count of instances.
### Detailed Analysis
**1. Errors o1 Mini (Left Chart)**
* **Wrong (Red):** Dominates the chart. **72.3% (86 instances)**. This is the largest single segment across all three charts.
* **Correct (Green):** The second-largest segment. **25.2% (30 instances)**.
* **Max Actions Error (Yellow):** A very small slice. **1.7% (2 instances)**.
* **Invalid JSON (Blue):** The smallest slice. **0.8% (1 instance)**.
* *Spatial Note:* The "Correct" slice is exploded (pulled out) from the pie. The "Invalid JSON" and "Max Actions Error" slices are very thin and located between the "Correct" and "Wrong" slices.
**2. Errors Claude 3.5 Sonnet (Center Chart)**
* **Wrong (Red):** The largest segment. **63.9% (76 instances)**.
* **Correct (Green):** A substantial segment. **36.1% (43 instances)**.
* **Invalid JSON & Max Actions Error:** These slices are **not present** in this chart, indicating zero recorded instances of these specific error types for this model in this test.
* *Spatial Note:* The "Correct" slice is exploded from the pie. The chart is simpler, containing only two segments.
**3. Errors LLAMA-3.1 70B (Right Chart)**
* **Wrong (Red):** The largest segment. **58.0% (69 instances)**.
* **Correct (Green):** The second-largest segment. **29.4% (35 instances)**.
* **Invalid JSON (Blue):** A notable segment. **9.2% (11 instances)**.
* **Max Actions Error (Yellow):** A small segment. **3.4% (4 instances)**.
* *Spatial Note:* The "Correct" slice is exploded from the pie. The "Invalid JSON" and "Max Actions Error" slices are clearly visible and located between the "Correct" and "Wrong" slices.
### Key Observations
1. **Performance Hierarchy:** In terms of the "Correct" rate, Claude 3.5 Sonnet (36.1%) > LLAMA-3.1 70B (29.4%) > o1 Mini (25.2%).
2. **Error Profile Variation:** The models exhibit distinct error profiles.
* **o1 Mini** has the highest overall error rate (74.8%) and is the only model with a non-zero "Max Actions Error" rate below 2%.
* **Claude 3.5 Sonnet** shows no instances of "Invalid JSON" or "Max Actions Error," suggesting its failures are purely in producing incorrect answers ("Wrong").
* **LLAMA-3.1 70B** has a significant "Invalid JSON" error rate (9.2%), which is an order of magnitude higher than o1 Mini's (0.8%).
3. **Dominant Failure Mode:** For all three models, the "Wrong" category is the largest segment, indicating that producing an incorrect answer is the most common failure mode, more common than technical errors like invalid JSON or hitting action limits.
### Interpretation
This data suggests a trade-off between different types of reliability in LLM-based search agents. **Claude 3.5 Sonnet** demonstrates the highest raw accuracy and perfect technical reliability (no JSON/action errors) in this specific test setup, but its failures are absolute (the answer is simply wrong). **LLAMA-3.1 70B** has a lower accuracy than Claude but exhibits a more diverse error profile, with a notable propensity for structural output failures (Invalid JSON). **o1 Mini** performs the worst in terms of accuracy and has a small but present rate of action-limit errors.
The absence of "Invalid JSON" and "Max Actions Error" for Claude 3.5 Sonnet could indicate superior instruction-following for output formatting and more efficient action planning. The high "Invalid JSON" rate for LLAMA-3.1 70B might point to challenges in consistently adhering to strict output schemas. The universal dominance of the "Wrong" category underscores that the core challenge in this task is generating correct information, not just formatting it correctly or managing the interaction loop. The "Search Only w/o Demo" condition likely removes helpful context, pushing models to rely purely on their parametric knowledge and search capabilities, which appears to be a significant point of failure for all three models tested.