## Diagram: MoBA Gating with Varlen Flash-Attention
### Overview
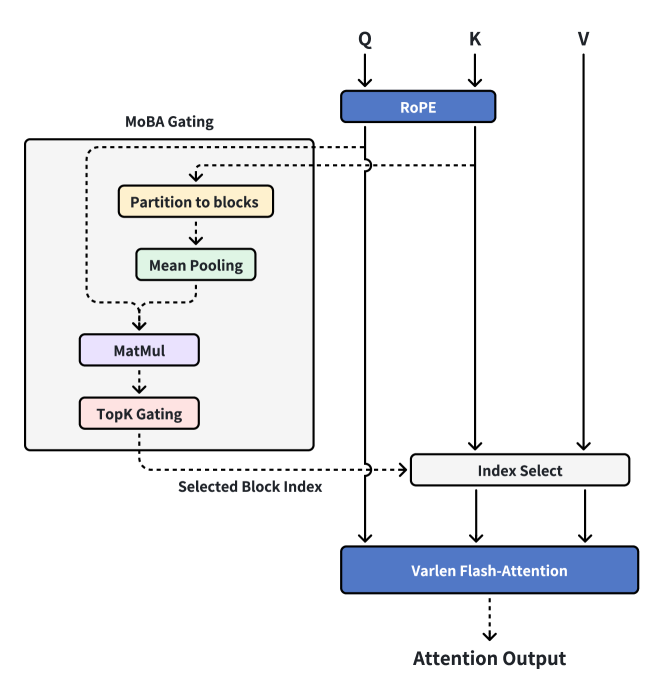
The diagram illustrates a process involving MoBA Gating, RoPE (Rotary Positional Embedding), Index Selection, and Varlen Flash-Attention, ultimately leading to an Attention Output. The diagram shows the flow of data and operations within this system.
### Components/Axes
* **MoBA Gating:** A module containing the following sub-modules:
* Partition to blocks
* Mean Pooling
* MatMul (Matrix Multiplication)
* TopK Gating
* **Q, K, V:** Inputs to the system.
* **RoPE:** Rotary Positional Embedding module.
* **Index Select:** A module that selects indices.
* **Varlen Flash-Attention:** A module performing variable-length flash attention.
* **Attention Output:** The final output of the system.
* **Selected Block Index:** Output from the MoBA Gating module.
### Detailed Analysis
1. **Inputs:**
* Q (Query) flows into the RoPE module.
* K (Key) flows directly to the Index Select module and then to the Varlen Flash-Attention module.
* V (Value) flows directly to the Index Select module and then to the Varlen Flash-Attention module.
2. **MoBA Gating:**
* The MoBA Gating module consists of a sequence of operations: Partition to blocks, Mean Pooling, MatMul, and TopK Gating.
* The output of the TopK Gating module, labeled "Selected Block Index," is fed into the Index Select module.
3. **RoPE:**
* The Q input is processed by the RoPE module.
* The output of the RoPE module flows to the Index Select module and then to the Varlen Flash-Attention module.
4. **Index Select:**
* The Index Select module receives input from RoPE (processed Q), K, V, and the "Selected Block Index" from the MoBA Gating module.
* The output of the Index Select module flows to the Varlen Flash-Attention module.
5. **Varlen Flash-Attention:**
* The Varlen Flash-Attention module receives input from the Index Select module.
* The output of the Varlen Flash-Attention module is the "Attention Output."
### Key Observations
* The MoBA Gating module appears to be responsible for selecting specific blocks of data, which are then used by the Index Select module.
* The RoPE module processes the Query (Q) input before it is used in the attention mechanism.
* The Index Select module combines the processed Q, K, V, and the selected block indices to prepare the data for the Varlen Flash-Attention module.
* The Varlen Flash-Attention module produces the final "Attention Output."
### Interpretation
The diagram illustrates a specific architecture for attention mechanisms, incorporating MoBA Gating for selective processing of input data. The MoBA Gating module likely aims to improve efficiency or focus the attention mechanism on relevant parts of the input. The use of RoPE suggests that positional information is important for the attention mechanism. The Varlen Flash-Attention module likely handles variable-length inputs, making the system more flexible. The overall architecture suggests a system designed for efficient and focused attention processing.