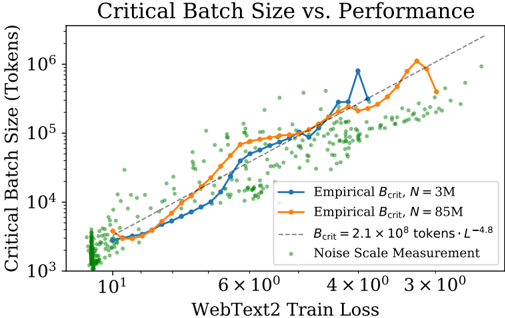
## Chart: Critical Batch Size vs. Performance
### Overview
The image is a scatter plot showing the relationship between critical batch size (in tokens) and WebText2 train loss. The plot includes two empirical data series for different values of N (3M and 85M), a theoretical curve, and noise scale measurements. Both axes are logarithmically scaled.
### Components/Axes
* **Title:** Critical Batch Size vs. Performance
* **Y-axis:** Critical Batch Size (Tokens) - Logarithmic scale from 10^3 to 10^6
* **X-axis:** WebText2 Train Loss - Logarithmic scale from approximately 5 to 3 x 10^3
* **Legend:** Located in the top-right of the chart.
* Blue: Empirical B\_crit, N = 3M
* Orange: Empirical B\_crit, N = 85M
* Dashed Gray: B\_crit = 2.1 x 10^8 tokens * L^-4.8
* Green Dots: Noise Scale Measurement
### Detailed Analysis
* **Empirical B\_crit, N = 3M (Blue):**
* Trend: Generally increasing with WebText2 Train Loss.
* Data Points:
* At approximately x=5, y ≈ 3 x 10^3
* At approximately x=10, y ≈ 6 x 10^3
* At approximately x=60, y ≈ 3 x 10^4
* At approximately x=200, y ≈ 4 x 10^4
* At approximately x=500, y ≈ 6 x 10^4
* At approximately x=1000, y ≈ 8 x 10^4
* At approximately x=2000, y ≈ 9 x 10^4
* At approximately x=3000, y ≈ 5 x 10^4
* **Empirical B\_crit, N = 85M (Orange):**
* Trend: Generally increasing with WebText2 Train Loss.
* Data Points:
* At approximately x=5, y ≈ 4 x 10^3
* At approximately x=10, y ≈ 5 x 10^3
* At approximately x=60, y ≈ 2 x 10^4
* At approximately x=200, y ≈ 3 x 10^4
* At approximately x=500, y ≈ 4 x 10^4
* At approximately x=1000, y ≈ 5 x 10^4
* At approximately x=2000, y ≈ 8 x 10^4
* At approximately x=3000, y ≈ 1 x 10^5
* **B\_crit = 2.1 x 10^8 tokens * L^-4.8 (Dashed Gray):**
* Trend: Increasing with WebText2 Train Loss.
* Data Points:
* At approximately x=5, y ≈ 4 x 10^3
* At approximately x=10, y ≈ 7 x 10^3
* At approximately x=60, y ≈ 3 x 10^4
* At approximately x=200, y ≈ 6 x 10^4
* At approximately x=500, y ≈ 8 x 10^4
* At approximately x=1000, y ≈ 1 x 10^5
* At approximately x=2000, y ≈ 1.5 x 10^5
* At approximately x=3000, y ≈ 1.7 x 10^5
* **Noise Scale Measurement (Green Dots):**
* Trend: Scattered, but generally increases with WebText2 Train Loss.
* Distribution: Densely clustered at lower WebText2 Train Loss values and more spread out at higher values.
### Key Observations
* The empirical critical batch sizes (N = 3M and N = 85M) generally increase with WebText2 Train Loss.
* The theoretical curve (B\_crit = 2.1 x 10^8 tokens * L^-4.8) also increases with WebText2 Train Loss and appears to be an upper bound for the empirical data.
* The noise scale measurements are scattered, indicating variability in the relationship between noise and train loss.
* The empirical data for N=85M is generally higher than for N=3M, suggesting that a larger N leads to a larger critical batch size.
### Interpretation
The chart suggests a positive correlation between critical batch size and WebText2 train loss. This implies that as the train loss increases, a larger batch size is needed to maintain performance. The theoretical curve provides a model for this relationship, while the noise scale measurements indicate the level of variability in the data. The difference between the N=3M and N=85M curves suggests that the size of the dataset (N) also influences the critical batch size. The data indicates that the critical batch size increases with train loss, and that the rate of increase is influenced by the size of the dataset. The noise scale measurements suggest that there is a degree of randomness in the relationship between train loss and critical batch size.