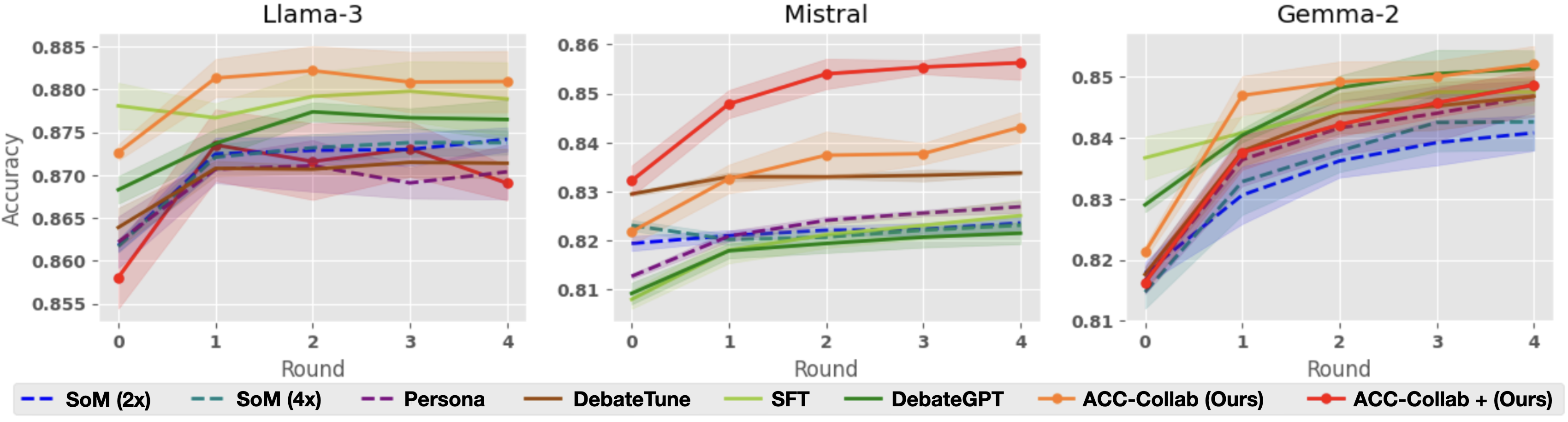
\n
## Line Chart: Accuracy vs. Round for Different Models and Training Methods
### Overview
The image presents three line charts, each displaying the accuracy of different language models (Llama-3, Mistral, and Gemma-2) across four rounds of evaluation. Each chart includes multiple lines representing different training methods applied to the respective model. The y-axis represents accuracy, and the x-axis represents the round number. Shaded areas around each line indicate confidence intervals.
### Components/Axes
* **X-axis:** "Round" with values 0, 1, 2, 3, and 4.
* **Y-axis:** "Accuracy" with a scale ranging from approximately 0.855 to 0.86 (Llama-3), 0.81 to 0.86 (Mistral), and 0.81 to 0.855 (Gemma-2).
* **Legends:** Each chart has a legend at the bottom identifying the different training methods/models.
* **Llama-3:** SoM (2x) - dashed dark blue, SoM (4x) - dashed light blue, Persona - solid green, DebateTune - solid dark green, SFT - solid light green, DebateGPT - solid yellow, ACC-Collab (Ours) - solid orange, ACC-Collab + (Ours) - dashed orange.
* **Mistral:** SoM (2x) - dashed dark blue, SoM (4x) - dashed light blue, Persona - solid green, DebateTune - solid dark green, SFT - solid light green, DebateGPT - solid yellow, ACC-Collab (Ours) - solid orange, ACC-Collab + (Ours) - dashed orange.
* **Gemma-2:** SoM (2x) - dashed dark blue, SoM (4x) - dashed light blue, Persona - solid green, DebateTune - solid dark green, SFT - solid light green, DebateGPT - solid yellow, ACC-Collab (Ours) - solid orange, ACC-Collab + (Ours) - dashed orange.
### Detailed Analysis or Content Details
**Llama-3 Chart:**
* **SoM (2x):** Starts at approximately 0.871, remains relatively stable around 0.870 across all rounds.
* **SoM (4x):** Starts at approximately 0.868, increases slightly to around 0.870 by round 2, then plateaus.
* **Persona:** Starts at approximately 0.866, increases to around 0.871 by round 2, then plateaus.
* **DebateTune:** Starts at approximately 0.864, increases to around 0.870 by round 2, then plateaus.
* **SFT:** Starts at approximately 0.863, increases to around 0.868 by round 2, then plateaus.
* **DebateGPT:** Starts at approximately 0.862, increases to around 0.867 by round 2, then plateaus.
* **ACC-Collab (Ours):** Starts at approximately 0.860, increases steadily to around 0.875 by round 4.
* **ACC-Collab + (Ours):** Starts at approximately 0.858, increases steadily to around 0.877 by round 4.
**Mistral Chart:**
* **SoM (2x):** Starts at approximately 0.823, increases to around 0.826 by round 1, then plateaus.
* **SoM (4x):** Starts at approximately 0.821, increases to around 0.825 by round 1, then plateaus.
* **Persona:** Starts at approximately 0.819, increases to around 0.825 by round 1, then plateaus.
* **DebateTune:** Starts at approximately 0.818, increases to around 0.824 by round 1, then plateaus.
* **SFT:** Starts at approximately 0.817, increases to around 0.823 by round 1, then plateaus.
* **DebateGPT:** Starts at approximately 0.816, increases to around 0.822 by round 1, then plateaus.
* **ACC-Collab (Ours):** Starts at approximately 0.820, increases steadily to around 0.850 by round 4.
* **ACC-Collab + (Ours):** Starts at approximately 0.819, increases steadily to around 0.855 by round 4.
**Gemma-2 Chart:**
* **SoM (2x):** Starts at approximately 0.832, increases to around 0.835 by round 1, then plateaus.
* **SoM (4x):** Starts at approximately 0.830, increases to around 0.834 by round 1, then plateaus.
* **Persona:** Starts at approximately 0.828, increases to around 0.833 by round 1, then plateaus.
* **DebateTune:** Starts at approximately 0.827, increases to around 0.832 by round 1, then plateaus.
* **SFT:** Starts at approximately 0.826, increases to around 0.831 by round 1, then plateaus.
* **DebateGPT:** Starts at approximately 0.825, increases to around 0.830 by round 1, then plateaus.
* **ACC-Collab (Ours):** Starts at approximately 0.824, increases steadily to around 0.848 by round 4.
* **ACC-Collab + (Ours):** Starts at approximately 0.823, increases steadily to around 0.852 by round 4.
### Key Observations
* In all three models, the "ACC-Collab (Ours)" and "ACC-Collab + (Ours)" methods consistently outperform other training methods, showing a clear upward trend in accuracy across rounds.
* The other training methods (SoM, Persona, DebateTune, SFT, DebateGPT) generally plateau in accuracy after round 1 or 2.
* Mistral starts with the lowest initial accuracy among the three models, but shows significant improvement with the "ACC-Collab" methods.
* Llama-3 starts with the highest initial accuracy, and the "ACC-Collab" methods provide incremental gains.
### Interpretation
The data suggests that the "ACC-Collab" training methods are highly effective in improving the accuracy of these language models, particularly over multiple rounds of evaluation. The consistent upward trend indicates that these methods allow the models to learn and refine their performance with continued exposure. The plateauing of other methods suggests they may reach a performance limit relatively quickly. The differences in initial accuracy and improvement rates between the models highlight the varying capabilities and sensitivities of each model to different training approaches. The "ACC-Collab +" method consistently outperforms the "ACC-Collab" method, suggesting that the additional component provides a further boost to performance. This data could be used to inform the selection of training methods for these models, with a strong recommendation for the "ACC-Collab" approaches. The confidence intervals (shaded areas) indicate the uncertainty in the accuracy measurements, but the overall trends remain clear.