TECHNICAL ASSET FINGERPRINT
1a65c95e749c8d0904528649
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
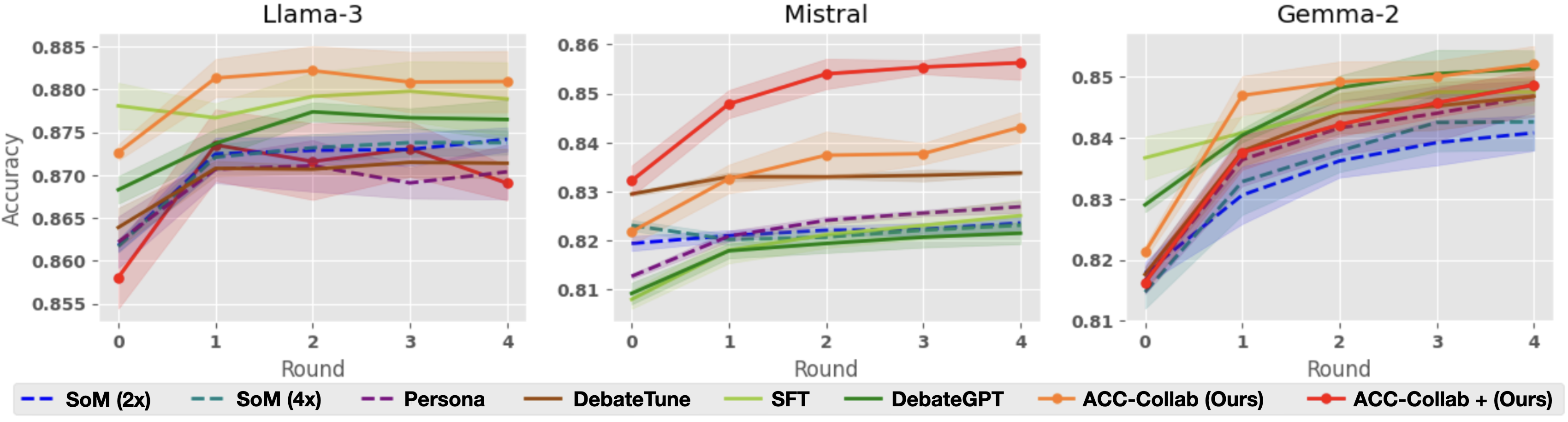
## Line Charts: Accuracy vs. Round for Three Language Models
### Overview
The image displays three side-by-side line charts comparing the performance of eight different methods across five rounds (0-4) for three distinct language models: Llama-3, Mistral, and Gemma-2. The y-axis represents "Accuracy," and the x-axis represents "Round." Each chart includes shaded regions around the lines, likely indicating confidence intervals or standard deviation. A shared legend at the bottom defines the eight methods.
### Components/Axes
* **Chart Titles (Top Center):** "Llama-3", "Mistral", "Gemma-2"
* **Y-Axis Label (Left Side, Vertical):** "Accuracy"
* **X-Axis Label (Bottom Center):** "Round"
* **X-Axis Markers:** 0, 1, 2, 3, 4
* **Y-Axis Scales:**
* Llama-3: 0.855 to 0.885 (increments of 0.005)
* Mistral: 0.81 to 0.86 (increments of 0.01)
* Gemma-2: 0.81 to 0.85 (increments of 0.01)
* **Legend (Bottom, spanning all charts):**
* **SoM (2x):** Blue dashed line (`--`)
* **SoM (4x):** Teal dashed line (`--`)
* **Persona:** Purple dashed line (`--`)
* **DebateTune:** Brown solid line
* **SFT:** Light green solid line
* **DebateGPT:** Dark green solid line
* **ACC-Collab (Ours):** Orange solid line with circular markers
* **ACC-Collab + (Ours):** Red solid line with circular markers
### Detailed Analysis
#### **Chart 1: Llama-3**
* **Trend Verification:** Most methods show an initial increase from Round 0 to Round 1, followed by a plateau or slight fluctuations. The orange line (ACC-Collab) shows the highest peak.
* **Data Points (Approximate):**
* **ACC-Collab (Ours) [Orange]:** Starts ~0.873 (R0), peaks ~0.882 (R2), ends ~0.881 (R4).
* **ACC-Collab + (Ours) [Red]:** Starts lowest ~0.858 (R0), rises sharply to ~0.873 (R1), fluctuates, ends ~0.869 (R4).
* **DebateGPT [Dark Green]:** Steady increase from ~0.868 (R0) to ~0.877 (R4).
* **SFT [Light Green]:** Starts high ~0.878 (R0), dips slightly, ends ~0.879 (R4).
* **DebateTune [Brown]:** Starts ~0.864 (R0), rises to ~0.871 (R1), plateaus.
* **SoM (2x) [Blue Dashed]:** Starts ~0.862 (R0), rises to ~0.874 (R1), ends ~0.874 (R4).
* **SoM (4x) [Teal Dashed]:** Follows a very similar path to SoM (2x).
* **Persona [Purple Dashed]:** Starts ~0.863 (R0), peaks ~0.872 (R1), declines to ~0.870 (R4).
#### **Chart 2: Mistral**
* **Trend Verification:** The red line (ACC-Collab+) shows a dominant, steep upward trend. The orange line (ACC-Collab) also rises steadily. Other methods show modest gains or remain relatively flat.
* **Data Points (Approximate):**
* **ACC-Collab + (Ours) [Red]:** Clear top performer. Starts ~0.832 (R0), rises steeply to ~0.856 (R4).
* **ACC-Collab (Ours) [Orange]:** Second highest. Starts ~0.822 (R0), rises to ~0.843 (R4).
* **DebateTune [Brown]:** Relatively flat, ~0.830 (R0) to ~0.834 (R4).
* **SoM (2x) [Blue Dashed]:** Starts ~0.820 (R0), ends ~0.824 (R4).
* **SoM (4x) [Teal Dashed]:** Very close to SoM (2x).
* **Persona [Purple Dashed]:** Starts lowest ~0.813 (R0), rises to ~0.827 (R4).
* **SFT [Light Green]:** Starts ~0.810 (R0), ends ~0.825 (R4).
* **DebateGPT [Dark Green]:** Starts ~0.809 (R0), ends ~0.822 (R4).
#### **Chart 3: Gemma-2**
* **Trend Verification:** All methods show a strong, consistent upward trend from Round 0 to Round 4. The lines are more tightly clustered than in the other charts, especially at later rounds.
* **Data Points (Approximate):**
* **ACC-Collab (Ours) [Orange]:** Top performer. Starts ~0.821 (R0), rises to ~0.852 (R4).
* **ACC-Collab + (Ours) [Red]:** Very close second. Starts ~0.816 (R0), rises to ~0.849 (R4).
* **SFT [Light Green]:** Strong performance. Starts ~0.837 (R0), ends ~0.851 (R4).
* **DebateGPT [Dark Green]:** Starts ~0.829 (R0), ends ~0.851 (R4).
* **DebateTune [Brown]:** Starts ~0.817 (R0), ends ~0.847 (R4).
* **Persona [Purple Dashed]:** Starts ~0.816 (R0), ends ~0.844 (R4).
* **SoM (4x) [Teal Dashed]:** Starts ~0.815 (R0), ends ~0.843 (R4).
* **SoM (2x) [Blue Dashed]:** Starts ~0.815 (R0), ends ~0.841 (R4).
### Key Observations
1. **Method Performance Hierarchy:** The proposed methods, **ACC-Collab (Ours)** and **ACC-Collab + (Ours)**, are consistently among the top performers across all three models.
2. **Model-Specific Behavior:**
* **Mistral:** Shows the most dramatic separation between methods. **ACC-Collab +** is the clear, dominant leader.
* **Gemma-2:** Shows the strongest overall improvement for all methods, with the highest final accuracy values and the tightest clustering of results.
* **Llama-3:** Shows more variability and less dramatic gains after Round 1 for most methods.
3. **Round 0 Baseline:** The starting accuracy (Round 0) varies significantly by model and method, indicating different baseline capabilities before the debate/round process begins.
4. **Trend Consistency:** With few exceptions (e.g., Persona in Llama-3), accuracy either improves or holds steady as rounds progress; no method shows a significant, sustained decline.
### Interpretation
This data demonstrates the effectiveness of the **ACC-Collab** family of methods for improving the accuracy of language models through a multi-round process, likely involving debate or collaboration. The key findings are:
* **Efficacy of Proposed Method:** The "Ours" methods (orange and red lines) generally outperform or match the other techniques (SoM, Persona, DebateTune, SFT, DebateGPT), suggesting the authors' approach is successful.
* **Importance of Model Architecture:** The same methods yield different relative performance gains on different base models (Llama-3, Mistral, Gemma-2). This implies that the effectiveness of collaborative/ debate-based training or inference is not universal but interacts with the underlying model's characteristics. Gemma-2 appears most receptive to these techniques.
* **Value of Iteration:** The general upward trend across rounds validates the core premise that iterative refinement (rounds) can boost accuracy. The most significant gains often occur in the first one to two rounds.
* **Stability vs. Peak Performance:** **ACC-Collab +** (red) achieves the highest single accuracy score on Mistral but is sometimes outperformed by its non-"+" variant (**ACC-Collab**, orange) on other models. This suggests a potential trade-off between peak performance and consistency across different tasks or models.
In summary, the charts provide strong evidence that the authors' collaborative methods enhance model accuracy through iterative rounds, with the degree of improvement being model-dependent. The results position ACC-Collab as a competitive technique in the landscape of methods designed to improve LLM reasoning or output quality.
DECODING INTELLIGENCE...