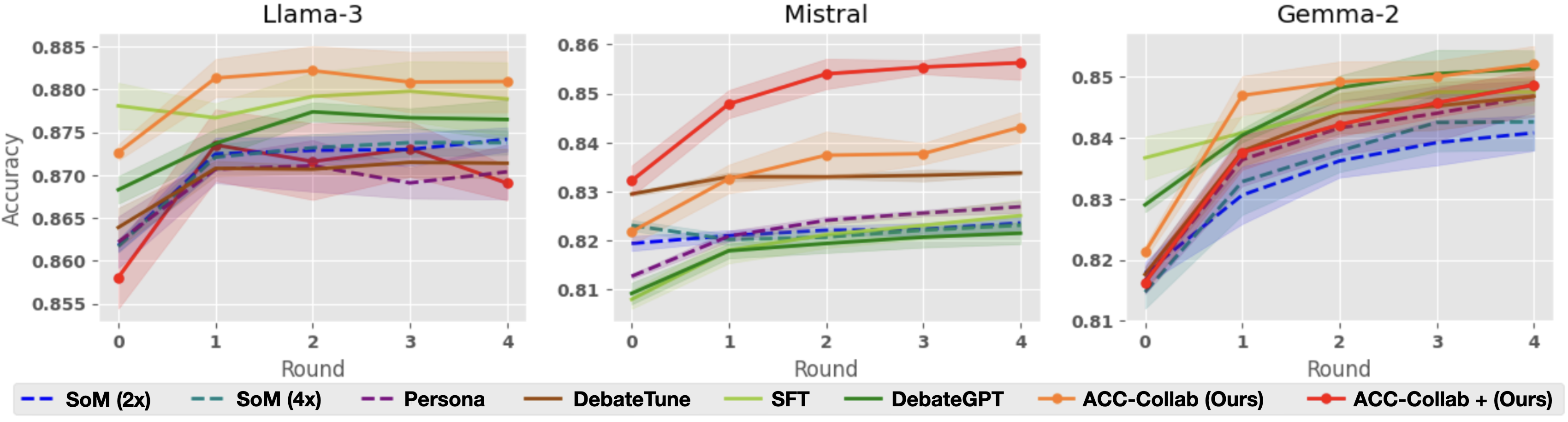
## Line Graphs: Model Accuracy Comparison Across Rounds
### Overview
Three side-by-side line graphs compare the accuracy of different AI models across four training rounds. Each graph represents a different base model (Llama-3, Mistral, Gemma-2) with multiple training approaches plotted against accuracy metrics. The graphs show progressive improvement in accuracy for most models, with shaded regions indicating confidence intervals.
### Components/Axes
- **X-axis**: "Round" (0 to 4) - Discrete training iterations
- **Y-axis**: "Accuracy" (0.855 to 0.885) - Performance metric
- **Legends**: Positioned at bottom of each graph with color-coded labels:
- **Blue**: SoM (2x)
- **Teal**: SoM (4x)
- **Purple**: Persona
- **Brown**: DebateTune
- **Green**: SFT
- **Dark Green**: DebateGPT
- **Orange**: ACC-Collab (Ours)
- **Red**: ACC-Collab + (Ours)
### Detailed Analysis
#### Llama-3 Graph
- **ACC-Collab (Ours)**: Starts at 0.873 (Round 0), peaks at 0.882 (Round 4)
- **ACC-Collab + (Ours)**: Begins at 0.858 (Round 0), rises to 0.878 (Round 4)
- **SoM (4x)**: Maintains steady 0.875-0.880 range
- **DebateGPT**: Shows gradual increase from 0.868 to 0.877
- **Confidence Intervals**: Widest for ACC-Collab + (Ours) in early rounds
#### Mistral Graph
- **ACC-Collab (Ours)**: Starts at 0.822 (Round 0), reaches 0.855 (Round 4)
- **ACC-Collab + (Ours)**: Begins at 0.831 (Round 0), peaks at 0.858 (Round 4)
- **DebateTune**: Flat line at 0.830-0.832
- **SFT**: Gradual rise from 0.815 to 0.828
- **Confidence Intervals**: Narrowest for ACC-Collab (Ours)
#### Gemma-2 Graph
- **ACC-Collab (Ours)**: Starts at 0.821 (Round 0), ends at 0.852 (Round 4)
- **ACC-Collab + (Ours)**: Begins at 0.815 (Round 0), reaches 0.855 (Round 4)
- **DebateGPT**: Sharp increase from 0.825 to 0.848
- **Persona**: Steady improvement from 0.818 to 0.842
- **Confidence Intervals**: Most variable for ACC-Collab + (Ours)
### Key Observations
1. **ACC-Collab + (Ours)** consistently outperforms base models across all three architectures
2. **SoM (4x)** shows highest stability in Llama-3 but underperforms in Mistral
3. **DebateGPT** demonstrates strongest growth in Gemma-2
4. **Confidence intervals** widen significantly for ACC-Collab + (Ours) in early rounds, suggesting greater uncertainty in initial training phases
5. **All models** show diminishing returns after Round 2, with accuracy plateaus observed in later rounds
### Interpretation
The data suggests that the ACC-Collab + (Ours) methodology provides the most significant accuracy improvements across different base architectures, particularly in early training rounds. The widening confidence intervals for this approach indicate higher variance in initial performance, which stabilizes as training progresses. While SoM (4x) shows promise in Llama-3, its performance is architecture-dependent. The consistent plateaus after Round 2 across all models suggest potential optimization limits or diminishing returns in the training methodology. The ACC-Collab (Ours) baseline demonstrates strong foundational performance, with the "+ (Ours)" enhancement providing additional gains through iterative refinement.