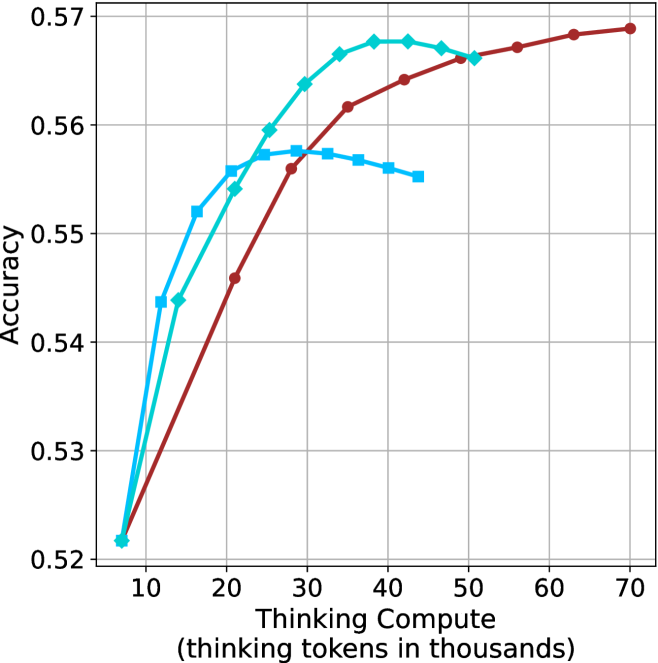
## Line Graph: Accuracy vs. Thinking Compute (Tokens in Thousands)
### Overview
The graph compares the accuracy of three computational models (Large, Medium, Small) across varying levels of "Thinking Compute" (measured in thousands of thinking tokens). All models start at similar accuracy levels but diverge in performance as compute increases.
### Components/Axes
- **X-axis**: "Thinking Compute (thinking tokens in thousands)"
- Scale: 10 to 70 (increments of 10)
- Labels: Numerical ticks at 10, 20, 30, 40, 50, 60, 70
- **Y-axis**: "Accuracy"
- Scale: 0.52 to 0.57 (increments of 0.01)
- Labels: Numerical ticks at 0.52, 0.53, 0.54, 0.55, 0.56, 0.57
- **Legend**: Top-right corner
- Colors:
- Red: "Large Model"
- Green: "Medium Model"
- Blue: "Small Model"
### Detailed Analysis
1. **Large Model (Red Line)**
- **Trend**: Steady upward slope from (10, 0.52) to (70, 0.57).
- **Key Points**:
- At 10k tokens: 0.52 accuracy
- At 30k tokens: ~0.56 accuracy
- At 70k tokens: 0.57 accuracy
2. **Medium Model (Green Line)**
- **Trend**: Rapid initial increase, then plateau.
- **Key Points**:
- At 10k tokens: 0.52 accuracy
- At 30k tokens: ~0.56 accuracy
- At 50k tokens: ~0.565 accuracy (plateau)
3. **Small Model (Blue Line)**
- **Trend**: Sharp rise, then decline, followed by stabilization.
- **Key Points**:
- At 10k tokens: 0.52 accuracy
- At 20k tokens: ~0.55 accuracy
- At 40k tokens: ~0.545 accuracy (dip)
- At 50k tokens: ~0.54 accuracy (stabilizes)
### Key Observations
- **Large Model Dominance**: The red line consistently outperforms others, showing linear improvement with compute.
- **Medium Model Efficiency**: The green line achieves near-peak accuracy (0.565) by 50k tokens but plateaus.
- **Small Model Limitations**: The blue line peaks early (20k tokens) but degrades with additional compute, suggesting diminishing returns or overfitting.
- **Convergence at Low Compute**: All models start at 0.52 accuracy at 10k tokens, indicating baseline performance parity.
### Interpretation
The data suggests that **larger models scale more effectively with increased compute**, maintaining higher accuracy across all token ranges. Medium models achieve strong performance but face diminishing returns beyond 30k tokens. Small models, while initially competitive, degrade with added compute, possibly due to architectural constraints or overfitting. This highlights a trade-off between model size, compute efficiency, and accuracy in computational tasks.
**Note**: All values are approximate, with uncertainty due to visual estimation from the graph.