\n
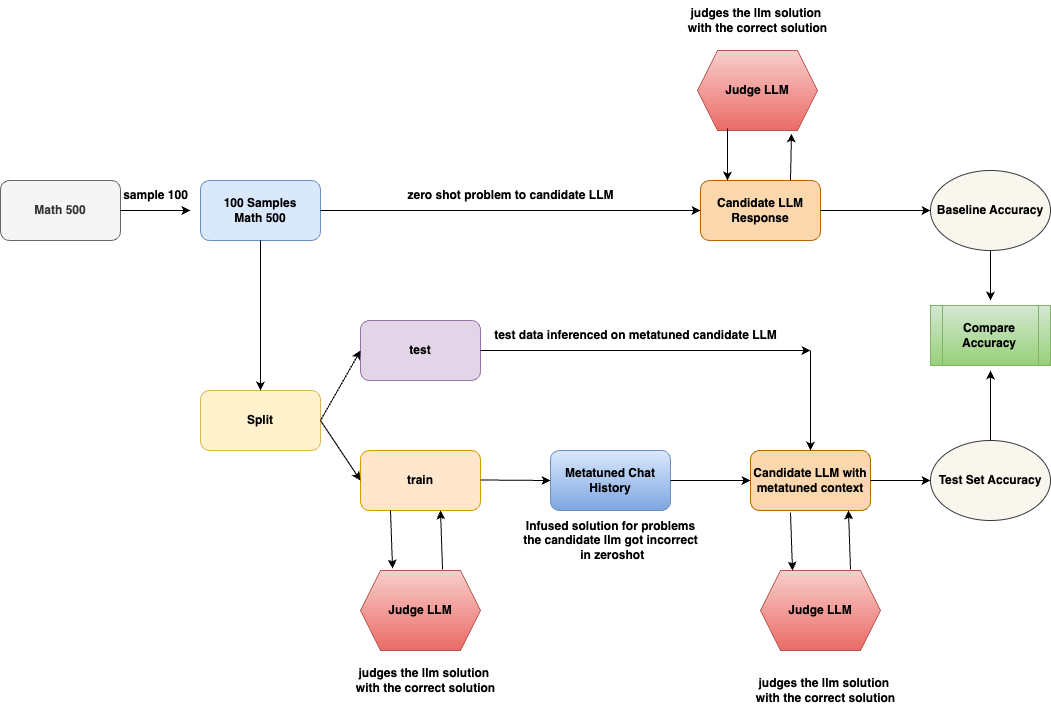
## Diagram: LLM Evaluation and Metatuning Workflow
### Overview
This diagram illustrates a workflow for evaluating and improving a Large Language Model (LLM) on mathematical problems. It details a process involving initial evaluation, splitting data into training and testing sets, metatuning the LLM, and comparing the accuracy of the original and metatuned models. The diagram uses colored boxes to represent different stages and components, with arrows indicating the flow of data and processes.
### Components/Axes
The diagram consists of the following key components:
* **Math 500:** The initial dataset of 500 mathematical problems.
* **Sample 100:** A subset of 100 problems sampled from Math 500.
* **100 Samples Math 500:** The 100 sampled problems.
* **Split:** A component that divides the data into "train" and "test" sets.
* **Judge LLM (Pink):** A component that evaluates the LLM's solutions against the correct answers. This appears three times in the diagram.
* **Candidate LLM Response (Orange):** The LLM's initial response to the problems.
* **Baseline Accuracy (Light Green):** The accuracy of the LLM before metatuning.
* **Metatuned Chat History (Yellow):** The LLM after being metatuned with additional context.
* **Candidate LLM with metatuned context (Orange):** The LLM's response after metatuning.
* **Test Set Accuracy (Light Green):** The accuracy of the LLM after metatuning.
* **Compare Accuracy (Light Green):** A component that compares the Baseline and Test Set Accuracy.
* **test data inferred on metatuned candidate LLM (Blue):** The test data used to evaluate the metatuned LLM.
* **train (Blue):** The training data used for metatuning.
The arrows indicate the direction of data flow and processing. Text labels along the arrows describe the actions performed at each step.
### Detailed Analysis or Content Details
The workflow begins with a dataset of "Math 500" problems. A sample of 100 problems ("Sample 100") is taken from this dataset. These 100 problems are then presented as a "zero shot problem" to the "Candidate LLM". The LLM's "Response" is then evaluated by a "Judge LLM", resulting in a "Baseline Accuracy".
The original dataset is then "Split" into "train" and "test" sets. The "train" set is used to create a "Metatuned Chat History" by infusing solutions for problems the candidate LLM initially got incorrect in the zero-shot phase. The "test" set is used to infer data on the metatuned candidate LLM. The metatuned LLM then generates a "Candidate LLM with metatuned context" response, which is again evaluated by a "Judge LLM", resulting in a "Test Set Accuracy". Finally, the "Baseline Accuracy" and "Test Set Accuracy" are "Compare[d]".
The text labels on the arrows provide further detail:
* "judges the llm solution with the correct solution" (appears three times)
* "zero shot problem to candidate LLM"
* "infused solution for problems the candidate llm got incorrect in zeroshot"
* "test data inferred on metatuned candidate LLM"
* "train"
### Key Observations
The diagram highlights a closed-loop process for improving LLM performance. The initial evaluation provides a baseline, and the metatuning step leverages the LLM's errors to refine its knowledge. The use of a "Judge LLM" ensures consistent and objective evaluation. The diagram emphasizes the importance of both zero-shot performance and the ability to learn from mistakes.
### Interpretation
This diagram demonstrates a methodology for iteratively improving an LLM's ability to solve mathematical problems. The process begins with a standard evaluation (zero-shot) and then employs a metatuning strategy that focuses on correcting the LLM's initial errors. This approach suggests that the goal is not simply to achieve high accuracy on a given dataset, but also to enhance the LLM's learning capabilities and its ability to generalize to new problems. The use of a separate "Judge LLM" is crucial for ensuring the fairness and reliability of the evaluation process. The diagram implies that metatuning can significantly improve the LLM's performance, as evidenced by the comparison of baseline and test set accuracies. The workflow is designed to be self-improving, as the errors identified during evaluation are used to refine the LLM's knowledge and improve its future performance.