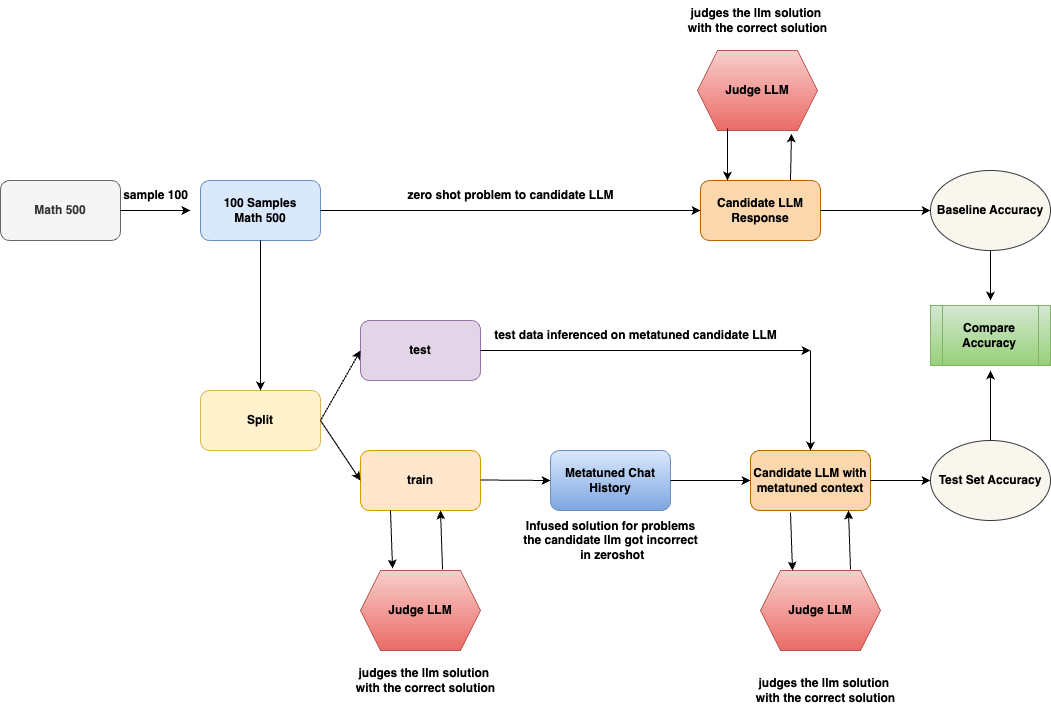
## Flowchart: Machine Learning Model Training and Evaluation Process
### Overview
The flowchart illustrates a machine learning pipeline for training and evaluating a language model (LLM) on mathematical problems. It includes data sampling, model training, testing, evaluation, and iterative refinement through feedback loops.
### Components/Axes
1. **Nodes**:
- **Math 500**: Source dataset.
- **100 Samples Math 500**: Subset of 100 problems sampled from Math 500.
- **Split**: Divides data into training and testing sets.
- **train**: Training subset.
- **test**: Testing subset.
- **Metatuned Chat History**: Repository of past model responses.
- **Candidate LLM**: Primary model under evaluation.
- **Candidate LLM with metatuned context**: Model augmented with historical data.
- **Judge LLM**: Evaluation component comparing responses to correct solutions.
- **Baseline Accuracy**: Initial model performance metric.
- **Test Set Accuracy**: Post-training performance metric.
- **Compare Accuracy**: Evaluation of improvement between baseline and test set.
2. **Arrows**:
- **sample 100**: Sampling 100 problems from Math 500.
- **zero shot problem to candidate LLM**: Initial model inference without training.
- **test data inferred on metatuned candidate LLM**: Model inference using historical data.
- **Infused solution for problems the candidate LLM got incorrect in zeroshot**: Feedback loop for retraining.
- **judges the llm solution with the correct solution**: Evaluation step.
### Detailed Analysis
1. **Data Flow**:
- **Math 500** → **100 Samples Math 500**: A subset of 100 problems is sampled.
- **Split**: Data is divided into **train** (for training) and **test** (for evaluation).
- **train** → **Metatuned Chat History**: Training data is used to refine the model.
- **test** → **Candidate LLM**: Model evaluates test data in a zero-shot scenario.
- **Candidate LLM** → **Judge LLM**: Responses are compared to correct solutions to compute **Baseline Accuracy**.
- **Judge LLM** → **Metatuned Chat History**: Incorrect responses are logged for retraining.
- **Metatuned Chat History** → **Candidate LLM with metatuned context**: Historical data is infused into the model.
- **Candidate LLM with metatuned context** → **Judge LLM**: Updated model is re-evaluated for **Test Set Accuracy**.
- **Judge LLM** → **Compare Accuracy**: Performance improvement is assessed.
2. **Feedback Loops**:
- Incorrect responses from the zero-shot **Candidate LLM** are used to retrain the model via **Metatuned Chat History**, creating an iterative refinement process.
### Key Observations
- The process emphasizes **iterative improvement** through feedback loops, where model errors are corrected using historical data.
- **Judge LLM** acts as a critical evaluator, comparing model outputs to ground-truth solutions.
- **Metatuned Chat History** serves as a knowledge base for contextualizing the model’s training.
### Interpretation
This flowchart represents a **self-improving machine learning system** for mathematical problem-solving. The **Judge LLM** ensures quality control by validating responses against correct solutions, while **Metatuned Chat History** enables the model to learn from past mistakes. The **Split** step highlights the importance of separating training and testing data to avoid overfitting. The **Compare Accuracy** step quantifies progress, suggesting a focus on measurable performance gains. The system’s design implies a balance between **zero-shot capabilities** (initial inference) and **metatuning** (contextual refinement), aiming to enhance accuracy over time through continuous learning.