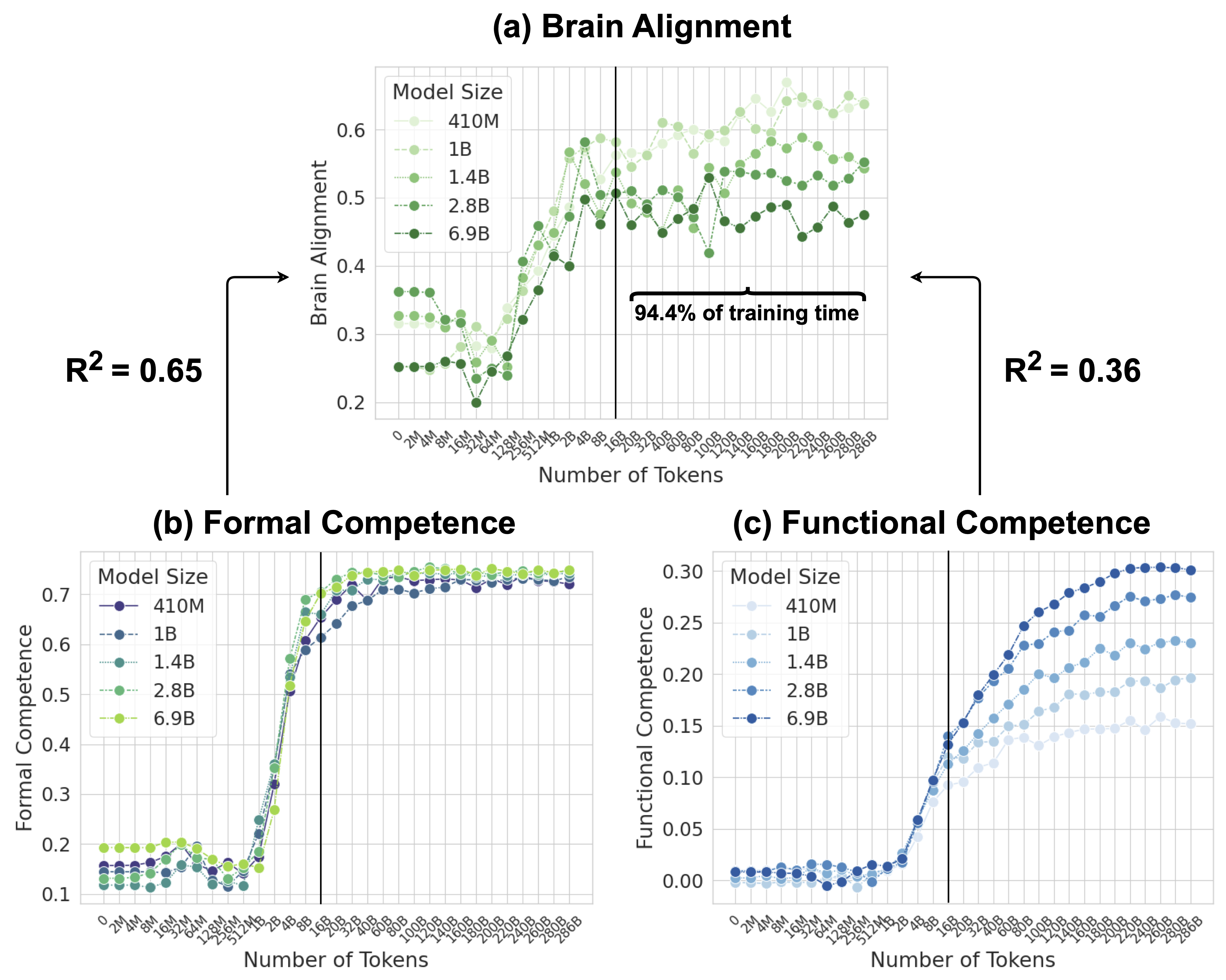
## Chart Type: Multiple Line Graphs
### Overview
The image presents three line graphs comparing the performance of different sized language models across various metrics as they are trained on increasing numbers of tokens. The graphs are titled "(a) Brain Alignment", "(b) Formal Competence", and "(c) Functional Competence". Each graph plots the metric on the y-axis against the number of tokens on the x-axis. The models are differentiated by line color and style, with a legend provided in each subplot. A vertical line indicates a point representing 94.4% of training time.
### Components/Axes
**General Components:**
* **Titles:** (a) Brain Alignment, (b) Formal Competence, (c) Functional Competence
* **Legends:** Located in the top-left corner of each subplot, indicating model size (410M, 1B, 1.4B, 2.8B, 6.9B) with corresponding line styles and colors.
* **Vertical Line:** A vertical black line is present in each graph, labeled "94.4% of training time" in the Brain Alignment graph.
* **R-squared values:** R^2 = 0.65 is present to the left of the Brain Alignment graph, and R^2 = 0.36 is present to the right.
**Graph (a) Brain Alignment:**
* **Y-axis:** "Brain Alignment", scale from 0.2 to 0.6, with ticks at 0.2, 0.3, 0.4, 0.5, and 0.6.
* **X-axis:** "Number of Tokens", with values ranging from 0 to 286B (billions). Specific values marked are 0, 2M, 4M, 8M, 16M, 32M, 64M, 128M, 256M, 512M, 1B, 2B, 4B, 8B, 16B, 20B, 32B, 40B, 60B, 80B, 100B, 120B, 140B, 160B, 180B, 200B, 220B, 240B, 260B, 280B, 286B.
* **Data Series:**
* **410M (light green):** Starts at approximately 0.25, increases to around 0.5 at 16B tokens, then fluctuates between 0.5 and 0.6.
* **1B (green):** Starts at approximately 0.25, increases to around 0.5 at 16B tokens, then fluctuates between 0.45 and 0.55.
* **1.4B (green-grey):** Starts at approximately 0.25, increases to around 0.45 at 16B tokens, then fluctuates between 0.4 and 0.5.
* **2.8B (dark green):** Starts at approximately 0.25, increases to around 0.45 at 16B tokens, then fluctuates between 0.4 and 0.5.
* **6.9B (darkest green):** Starts at approximately 0.35, increases to around 0.45 at 16B tokens, then fluctuates between 0.4 and 0.5.
**Graph (b) Formal Competence:**
* **Y-axis:** "Formal Competence", scale from 0.1 to 0.7, with ticks at 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, and 0.7.
* **X-axis:** "Number of Tokens", with values ranging from 0 to 286B (billions). Specific values marked are 0, 2M, 4M, 8M, 16M, 32M, 64M, 128M, 256M, 512MB, 1B, 2B, 4B, 8B, 16B, 20B, 32B, 40B, 60B, 80B, 100B, 120B, 140B, 160B, 180B, 200B, 220B, 240B, 260B, 280B, 286B.
* **Data Series:**
* **410M (dark blue):** Starts at approximately 0.15, increases sharply to around 0.65 at 16B tokens, then plateaus around 0.7.
* **1B (blue-grey):** Starts at approximately 0.15, increases sharply to around 0.65 at 16B tokens, then plateaus around 0.7.
* **1.4B (green-grey):** Starts at approximately 0.15, increases sharply to around 0.65 at 16B tokens, then plateaus around 0.7.
* **2.8B (light green):** Starts at approximately 0.15, increases sharply to around 0.65 at 16B tokens, then plateaus around 0.7.
* **6.9B (yellow-green):** Starts at approximately 0.2, increases sharply to around 0.65 at 16B tokens, then plateaus around 0.7.
**Graph (c) Functional Competence:**
* **Y-axis:** "Functional Competence", scale from 0.00 to 0.30, with ticks at 0.00, 0.05, 0.10, 0.15, 0.20, 0.25, and 0.30.
* **X-axis:** "Number of Tokens", with values ranging from 0 to 286B (billions). Specific values marked are 0, 2M, 4M, 8M, 16M, 32M, 64M, 128M, 256M, 5120, 1B, 2B, 4B, 8B, 16B, 20B, 32B, 40B, 60B, 80B, 100B, 120B, 140B, 160B, 180B, 200B, 220B, 240B, 260B, 280B, 286B.
* **Data Series:**
* **410M (lightest blue):** Starts at approximately 0.01, increases to around 0.15 at 16B tokens, then plateaus around 0.17.
* **1B (light blue):** Starts at approximately 0.01, increases to around 0.20 at 16B tokens, then plateaus around 0.22.
* **1.4B (blue):** Starts at approximately 0.01, increases to around 0.23 at 16B tokens, then plateaus around 0.25.
* **2.8B (dark blue):** Starts at approximately 0.01, increases to around 0.27 at 16B tokens, then plateaus around 0.28.
* **6.9B (darkest blue):** Starts at approximately 0.01, increases to around 0.30 at 16B tokens, then plateaus around 0.31.
### Key Observations
* **Brain Alignment:** The brain alignment metric shows an initial increase for all model sizes, followed by fluctuations. The R^2 value of 0.65 suggests a moderate correlation.
* **Formal Competence:** All models exhibit a sharp increase in formal competence around 16B tokens, after which they plateau. The R^2 value is not provided for this graph.
* **Functional Competence:** Functional competence also increases sharply around 16B tokens, with larger models achieving higher levels of competence. The R^2 value of 0.36 suggests a weak correlation.
* **Model Size Impact:** Larger models generally achieve higher levels of formal and functional competence. The impact of model size on brain alignment is less clear.
* **Training Time Threshold:** The vertical line at 94.4% of training time appears to coincide with the point where the models begin to plateau in formal and functional competence.
### Interpretation
The data suggests that increasing the number of training tokens significantly improves the formal and functional competence of language models, particularly up to a certain point (around 16B tokens or 94.4% of training time). After this point, the gains diminish, and the models plateau. Larger models tend to perform better in terms of formal and functional competence, indicating that model size is also a crucial factor. The brain alignment metric shows a less clear relationship with model size and training tokens, suggesting that it may be influenced by other factors or require a different analysis approach. The R^2 values indicate the strength of the relationship between the number of tokens and the metrics, with higher values indicating a stronger correlation.