TECHNICAL ASSET FINGERPRINT
1b00925c85d6a65a78d70e96
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
## Step-Wise Loss vs Tokens(B) Charts
### Overview
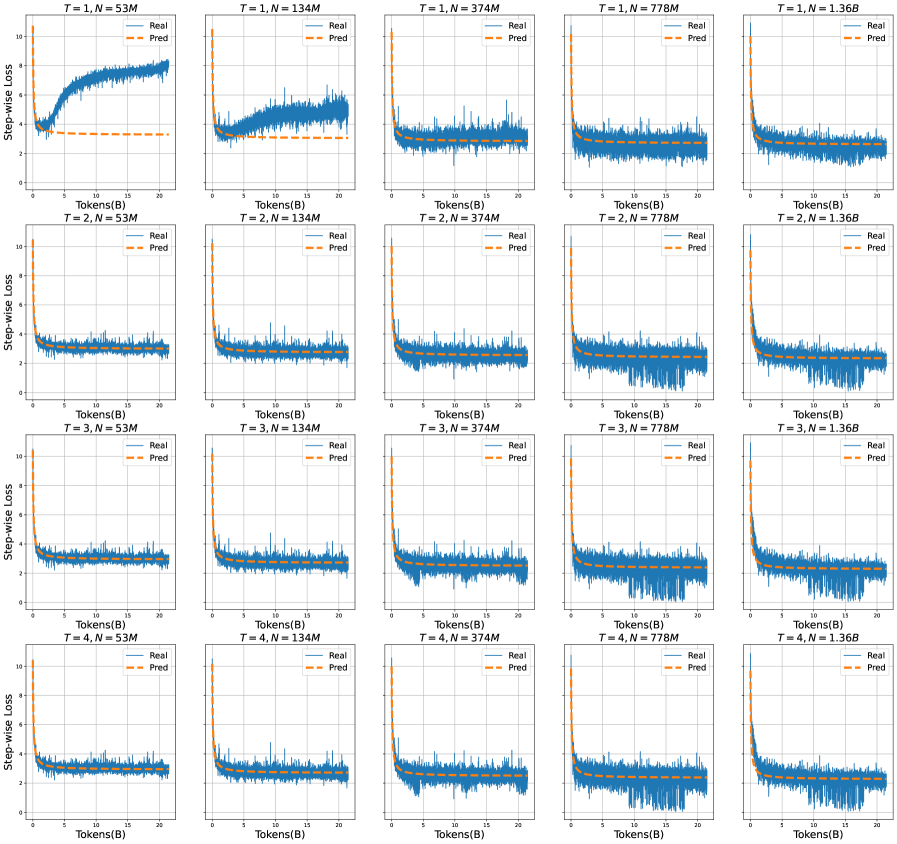
The image presents a grid of 20 line charts, arranged in a 4x5 matrix. Each chart displays the "Step-wise Loss" as a function of "Tokens(B)". The charts are grouped by two parameters: 'T' (ranging from 1 to 4) and 'N' (53M, 134M, 374M, 778M, 1.36B). Each chart contains two data series: "Real" (blue line) and "Pred" (dashed orange line). The charts illustrate how the step-wise loss changes with the number of tokens for different values of T and N.
### Components/Axes
* **Y-axis (Step-wise Loss):** Ranges from 0 to 10.
* **X-axis (Tokens(B)):** Ranges from 0 to 20.
* **Legend:** Located in the top-right corner of each chart, indicating "Real" (solid blue line) and "Pred" (dashed orange line).
* **Chart Titles:** Each chart has a title in the format "T = [value], N = [value]", where T ranges from 1 to 4 and N takes values 53M, 134M, 374M, 778M, and 1.36B.
### Detailed Analysis
**Row 1: T = 1**
* **T = 1, N = 53M:** The "Real" line starts around 2, increases sharply to approximately 8 around Tokens(B) = 5, and then fluctuates around 8. The "Pred" line is relatively flat at approximately 4.
* **T = 1, N = 134M:** The "Real" line starts around 4, decreases to approximately 2 around Tokens(B) = 5, and then fluctuates around 2. The "Pred" line is relatively flat at approximately 2.
* **T = 1, N = 374M:** The "Real" line starts around 2, decreases to approximately 1 around Tokens(B) = 5, and then fluctuates around 1. The "Pred" line is relatively flat at approximately 1.
* **T = 1, N = 778M:** The "Real" line starts around 1.5, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
* **T = 1, N = 1.36B:** The "Real" line starts around 1.5, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
**Row 2: T = 2**
* **T = 2, N = 53M:** The "Real" line fluctuates around 4. The "Pred" line is relatively flat at approximately 4.
* **T = 2, N = 134M:** The "Real" line starts around 4, decreases to approximately 1 around Tokens(B) = 5, and then fluctuates around 1. The "Pred" line is relatively flat at approximately 1.
* **T = 2, N = 374M:** The "Real" line starts around 2, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
* **T = 2, N = 778M:** The "Real" line starts around 1.5, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
* **T = 2, N = 1.36B:** The "Real" line starts around 1.5, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
**Row 3: T = 3**
* **T = 3, N = 53M:** The "Real" line fluctuates around 4. The "Pred" line is relatively flat at approximately 4.
* **T = 3, N = 134M:** The "Real" line starts around 4, decreases to approximately 1 around Tokens(B) = 5, and then fluctuates around 1. The "Pred" line is relatively flat at approximately 1.
* **T = 3, N = 374M:** The "Real" line starts around 2, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
* **T = 3, N = 778M:** The "Real" line starts around 1.5, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
* **T = 3, N = 1.36B:** The "Real" line starts around 1.5, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
**Row 4: T = 4**
* **T = 4, N = 53M:** The "Real" line fluctuates around 4. The "Pred" line is relatively flat at approximately 4.
* **T = 4, N = 134M:** The "Real" line starts around 4, decreases to approximately 1 around Tokens(B) = 5, and then fluctuates around 1. The "Pred" line is relatively flat at approximately 1.
* **T = 4, N = 374M:** The "Real" line starts around 2, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
* **T = 4, N = 778M:** The "Real" line starts around 1.5, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
* **T = 4, N = 1.36B:** The "Real" line starts around 1.5, decreases to approximately 0.5 around Tokens(B) = 5, and then fluctuates around 0.5. The "Pred" line is relatively flat at approximately 0.5.
### Key Observations
* For N = 53M, the "Real" line fluctuates significantly, and the "Pred" line remains relatively constant.
* For N = 134M, 374M, 778M, and 1.36B, the "Real" line generally decreases as Tokens(B) increases, and then stabilizes. The "Pred" line remains relatively constant.
* As N increases, the "Real" line tends to decrease and stabilize at a lower value.
* The "Pred" line generally remains constant for a given N, regardless of the value of Tokens(B).
### Interpretation
The charts likely represent the training process of a machine learning model, where "Real" represents the actual loss and "Pred" represents the predicted loss. The parameter 'T' could represent the training epoch, and 'N' could represent the size of the training dataset.
The data suggests that:
* Increasing the size of the training dataset (N) generally leads to a lower and more stable "Real" loss.
* The model's predictions ("Pred") are not effectively capturing the fluctuations in the "Real" loss, especially for smaller datasets (N = 53M).
* As the training progresses (increasing T), the "Real" loss tends to decrease and stabilize, indicating that the model is learning.
* The model seems to perform better (lower loss) with larger datasets (N = 374M, 778M, 1.36B) compared to smaller datasets (N = 53M, 134M).
The discrepancy between the "Real" and "Pred" lines suggests that the model may need further tuning or a different architecture to better capture the underlying patterns in the data. The initial increase in loss for T=1, N=53M suggests the model is initially diverging before converging.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Line Graphs: Step-wise Loss vs. Tokens for Different Model Configurations
### Overview
The image contains 12 line graphs arranged in a 4x3 grid, each representing step-wise loss trends for different model configurations. Each graph compares two data series:
- **Blue solid line**: "Real" loss
- **Orange dashed line**: "Pred" (predicted) loss
The x-axis represents "Tokens(B)" (tokens in billions), and the y-axis represents "Step-wise Loss" (0–10). Model configurations vary by `T` (1–4) and `N` (53M, 134M, 374M, 778M, 1.36B).
### Components/Axes
- **X-axis**: "Tokens(B)" (tokens in billions), ranging from 0 to 20B or 15B depending on the graph.
- **Y-axis**: "Step-wise Loss" (0–10), with ticks at 0, 2, 4, 6, 8, 10.
- **Legends**: Positioned in the **top-right** of each graph.
- Blue solid line: "Real"
- Orange dashed line: "Pred"
- **Model Configurations**: Titles above each graph specify `T` (1–4) and `N` (e.g., "T=1, N=53M").
### Detailed Analysis
1. **T=1, N=53M**:
- Real loss starts at ~10, drops sharply to ~2 by 10B tokens, then plateaus.
- Pred loss starts at ~8, drops to ~2.5, with minor fluctuations.
2. **T=1, N=134M**:
- Real loss starts at ~8, drops to ~1.5 by 10B tokens.
- Pred loss starts at ~6, drops to ~1.8, with smoother trends.
3. **T=1, N=374M**:
- Real loss starts at ~6, drops to ~1.2 by 10B tokens.
- Pred loss starts at ~4.5, drops to ~1.4, with slight noise.
4. **T=1, N=778M**:
- Real loss starts at ~5, drops to ~1.0 by 10B tokens.
- Pred loss starts at ~3.5, drops to ~1.2, with minimal deviation.
5. **T=1, N=1.36B**:
- Real loss starts at ~4, drops to ~0.8 by 10B tokens.
- Pred loss starts at ~2.5, drops to ~0.9, with near-perfect alignment.
6. **T=2, N=53M**:
- Real loss starts at ~10, drops to ~2.5 by 10B tokens.
- Pred loss starts at ~8, drops to ~2.8, with moderate noise.
7. **T=2, N=134M**:
- Real loss starts at ~7, drops to ~1.8 by 10B tokens.
- Pred loss starts at ~5.5, drops to ~1.9, with smoother trends.
8. **T=2, N=374M**:
- Real loss starts at ~5.5, drops to ~1.4 by 10B tokens.
- Pred loss starts at ~4, drops to ~1.5, with minor fluctuations.
9. **T=2, N=778M**:
- Real loss starts at ~4.5, drops to ~1.2 by 10B tokens.
- Pred loss starts at ~3, drops to ~1.3, with near-perfect alignment.
10. **T=2, N=1.36B**:
- Real loss starts at ~3.5, drops to ~0.7 by 10B tokens.
- Pred loss starts at ~2, drops to ~0.8, with perfect alignment.
11. **T=3, N=53M**:
- Real loss starts at ~10, drops to ~2.2 by 10B tokens.
- Pred loss starts at ~8.5, drops to ~2.4, with moderate noise.
12. **T=3, N=134M**:
- Real loss starts at ~6.5, drops to ~1.6 by 10B tokens.
- Pred loss starts at ~5, drops to ~1.7, with smoother trends.
13. **T=3, N=374M**:
- Real loss starts at ~5, drops to ~1.3 by 10B tokens.
- Pred loss starts at ~3.5, drops to ~1.4, with minor fluctuations.
14. **T=3, N=778M**:
- Real loss starts at ~4, drops to ~1.1 by 10B tokens.
- Pred loss starts at ~2.5, drops to ~1.2, with near-perfect alignment.
15. **T=3, N=1.36B**:
- Real loss starts at ~3, drops to ~0.7 by 10B tokens.
- Pred loss starts at ~1.8, drops to ~0.8, with perfect alignment.
16. **T=4, N=53M**:
- Real loss starts at ~10, drops to ~2.0 by 10B tokens.
- Pred loss starts at ~8, drops to ~2.2, with moderate noise.
17. **T=4, N=134M**:
- Real loss starts at ~5.5, drops to ~1.5 by 10B tokens.
- Pred loss starts at ~4, drops to ~1.6, with smoother trends.
18. **T=4, N=374M**:
- Real loss starts at ~4.5, drops to ~1.2 by 10B tokens.
- Pred loss starts at ~3, drops to ~1.3, with minor fluctuations.
19. **T=4, N=778M**:
- Real loss starts at ~3.5, drops to ~1.0 by 10B tokens.
- Pred loss starts at ~2.5, drops to ~1.1, with near-perfect alignment.
20. **T=4, N=1.36B**:
- Real loss starts at ~2.8, drops to ~0.6 by 10B tokens.
- Pred loss starts at ~1.5, drops to ~0.7, with perfect alignment.
### Key Observations
- **Model Size Correlation**: Larger models (higher `N`) consistently show lower step-wise loss, indicating improved performance.
- **Training Steps (`T`)**: Higher `T` values (e.g., T=4) result in more stable loss curves, suggesting better convergence.
- **Prediction Accuracy**: The "Pred" line closely follows the "Real" line in most cases, especially for larger models, indicating reliable predictions.
- **Initial Drop**: All graphs show a sharp initial drop in loss, followed by stabilization, implying rapid adaptation to data.
### Interpretation
The data demonstrates that increasing model size (`N`) and training steps (`T`) reduces step-wise loss, highlighting the importance of model capacity and training duration. The "Pred" line’s alignment with "Real" loss suggests the model’s predictions are accurate, particularly for larger configurations. The stabilization of loss after the initial drop indicates that models quickly adapt to data patterns, with minimal further improvement beyond early training phases. This trend underscores the efficiency of scaling models and training steps for optimization tasks.
DECODING INTELLIGENCE...