TECHNICAL ASSET FINGERPRINT
1b32be8b64b614283b8b3f29
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
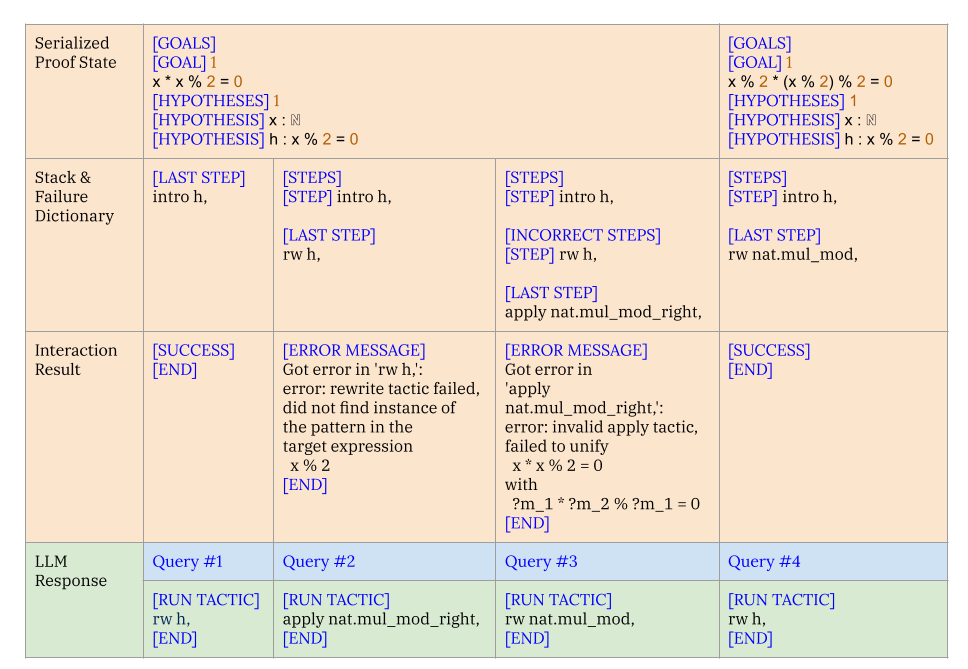
## Table: Proof Assistant Interaction Log
### Overview
The image displays a structured table documenting four sequential interactions (Query #1 through #4) with an automated theorem proving or proof assistant system. The table logs the state of a mathematical proof, the steps attempted, the results of those attempts, and the corresponding language model (LLM) generated responses. The content is technical, involving formal logic, tactics, and error messages.
### Components/Axes
The table is organized into four primary rows (categories) and four columns (queries/steps).
**Row Headers (Leftmost Column):**
1. **Serialized Proof State**: Contains the formal goal and hypotheses for the proof at each step.
2. **Stack & Failure Dictionary**: Logs the sequence of proof steps (tactics) applied and any failure information.
3. **Interaction Result**: Shows the outcome of the attempted step, either `[SUCCESS]` or an `[ERROR MESSAGE]`.
4. **LLM Response**: Shows the tactic command generated by the Language Model for that query.
**Column Headers (Top Row):**
The columns are implicitly labeled by the "LLM Response" row as:
* **Query #1**
* **Query #2**
* **Query #3**
* **Query #4**
**Cell Content Format:**
Text within cells is structured with bracketed labels (e.g., `[GOALS]`, `[STEP]`, `[ERROR MESSAGE]`) followed by content. Mathematical expressions use standard notation (e.g., `x * x % 2 = 0`).
### Detailed Analysis
#### **Row 1: Serialized Proof State**
* **Query #1 & #2 Column (Shared State):**
* `[GOALS]`
* `[GOAL] 1`
* `x * x % 2 = 0`
* `[HYPOTHESES] 1`
* `[HYPOTHESIS] x : ℕ` (The symbol `ℕ` denotes natural numbers).
* `[HYPOTHESIS] h : x % 2 = 0`
* **Query #3 & #4 Column (Shared State):**
* `[GOALS]`
* `[GOAL] 1`
* `x % 2 * (x % 2) % 2 = 0`
* `[HYPOTHESES] 1`
* `[HYPOTHESIS] x : ℕ`
* `[HYPOTHESIS] h : x % 2 = 0`
**Trend Verification:** The proof goal changes between Query #2 and #3. The initial goal (`x * x % 2 = 0`) is transformed into a more specific form (`x % 2 * (x % 2) % 2 = 0`), likely as a result of applying a rewrite rule.
#### **Row 2: Stack & Failure Dictionary**
* **Query #1:**
* `[LAST STEP]`
* `intro h,`
* **Query #2:**
* `[STEPS]`
* `[STEP] intro h,`
* `[LAST STEP]`
* `rw h,`
* **Query #3:**
* `[STEPS]`
* `[STEP] intro h,`
* `[INCORRECT STEPS]`
* `[STEP] rw h,`
* `[LAST STEP]`
* `apply nat.mul_mod_right,`
* **Query #4:**
* `[STEPS]`
* `[STEP] intro h,`
* `[LAST STEP]`
* `rw nat.mul_mod,`
**Component Isolation:** This row shows a history. Query #1 starts with `intro h`. Query #2 adds `rw h`. Query #3 marks `rw h` as incorrect and attempts `apply nat.mul_mod_right`. Query #4 shows a different final step: `rw nat.mul_mod`.
#### **Row 3: Interaction Result**
* **Query #1:**
* `[SUCCESS]`
* `[END]`
* **Query #2:**
* `[ERROR MESSAGE]`
* `Got error in 'rw h,':`
* `error: rewrite tactic failed, did not find instance of the pattern in the target expression`
* `x % 2`
* `[END]`
* **Query #3:**
* `[ERROR MESSAGE]`
* `Got error in 'apply nat.mul_mod_right,':`
* `error: invalid apply tactic, failed to unify`
* `x * x % 2 = 0`
* `with`
* `?m_1 * ?m_2 % ?m_1 = 0`
* `[END]`
* **Query #4:**
* `[SUCCESS]`
* `[END]`
**Trend Verification:** The results show a sequence: Success -> Failure (pattern match error) -> Failure (unification error) -> Success. The error messages provide specific technical reasons for the failures.
#### **Row 4: LLM Response**
* **Query #1:**
* `[RUN TACTIC]`
* `rw h,`
* `[END]`
* **Query #2:**
* `[RUN TACTIC]`
* `apply nat.mul_mod_right,`
* `[END]`
* **Query #3:**
* `[RUN TACTIC]`
* `rw nat.mul_mod,`
* `[END]`
* **Query #4:**
* `[RUN TACTIC]`
* `rw h,`
* `[END]`
**Spatial Grounding & Cross-Reference:** The LLM Response for a given query column dictates the tactic that was attempted, the result of which is logged in the "Interaction Result" row directly above it. For example, in the Query #2 column, the LLM suggested `apply nat.mul_mod_right,` (Row 4), which resulted in the error message in Row 3.
### Key Observations
1. **Proof State Evolution:** The core mathematical goal is transformed from `x * x % 2 = 0` to `x % 2 * (x % 2) % 2 = 0` between Query #2 and #3. This is a logical consequence of the hypothesis `h : x % 2 = 0`.
2. **Tactic Failure Patterns:** Two distinct failure modes are documented:
* **Query #2 Failure:** A `rw` (rewrite) tactic failed because the system could not find the pattern `x % 2` in the target expression `x * x % 2 = 0`. This suggests the expression was not in a form where the hypothesis could be directly applied.
* **Query #3 Failure:** An `apply` tactic failed due to a unification error. The system could not match the goal `x * x % 2 = 0` with the expected pattern of the lemma `nat.mul_mod_right`, which is `?m_1 * ?m_2 % ?m_1 = 0`.
3. **Successful Steps:** The proof begins successfully with `intro h` (introducing the hypothesis). It concludes successfully in Query #4 with `rw nat.mul_mod`, which likely rewrites the goal using a modular arithmetic theorem (`nat.mul_mod`).
4. **LLM Adaptation:** The LLM generates different tactics in response to errors. After the `rw h` failure in Query #2, it tries `apply nat.mul_mod_right` in Query #3. After that fails, it tries `rw nat.mul_mod` in Query #4, which succeeds.
### Interpretation
This table provides a Peircean investigative trace of a formal proof attempt, revealing the iterative, diagnostic process inherent in automated reasoning.
* **What the data suggests:** It demonstrates a common workflow in interactive theorem proving: state a goal, apply a tactic, receive feedback (success or a detailed error), and adapt the next tactic based on that feedback. The errors are not mere failures but informative signals about the mismatch between the current proof state and the preconditions of the chosen tactic.
* **How elements relate:** The "Serialized Proof State" is the ground truth. The "LLM Response" is a proposed action on that state. The "Stack & Failure Dictionary" is the action history. The "Interaction Result" is the system's evaluation of the proposed action against the current state. This forms a closed feedback loop.
* **Notable anomalies/outliers:** The shift in the proof goal between Query #2 and #3 is the most significant event. It indicates that an implicit step (likely a rewrite using hypothesis `h`) occurred successfully *between* the logged interactions, changing the goal's form. The subsequent errors then occur on this *new* goal. The final success with `rw nat.mul_mod` suggests the proof was completed by applying a general theorem about multiplication and modulus, rather than directly using the hypothesis `h` via rewrite.
* **Underlying information exposed:** The log exposes the "reasoning" of both the human/LLM (choosing tactics) and the proof assistant (enforcing logical rigor through pattern matching and unification). It highlights that successful proof search often requires finding the right *representation* of a problem (as seen in the goal transformation) and the right *lemma* to apply (as seen in the final successful step).
DECODING INTELLIGENCE...