# Technical Data Extraction: Model Performance Comparison
## 1. Document Overview
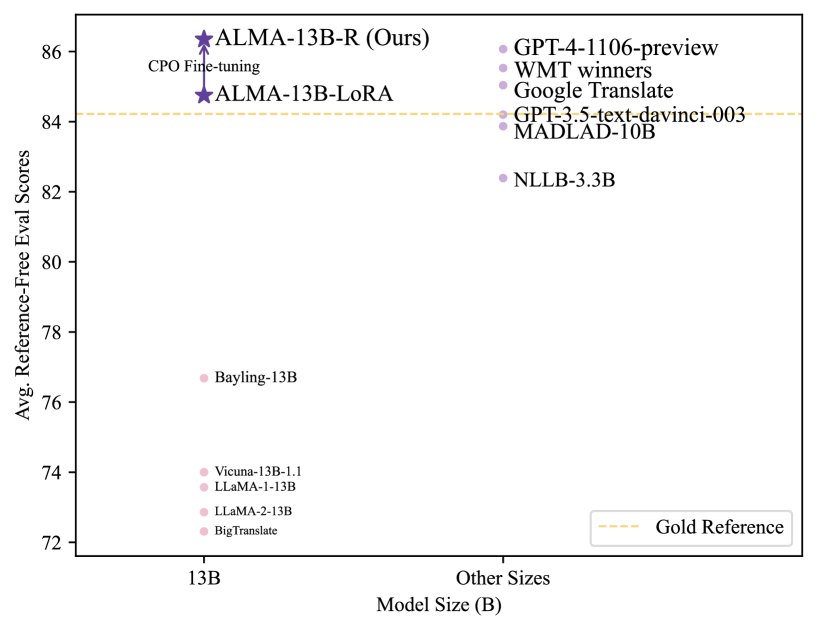
This image is a scatter plot comparing various Large Language Models (LLMs) based on their parameter size and their performance on translation tasks, measured by "Avg. Reference-Free Eval Scores." The chart specifically highlights the performance of the "ALMA" model series relative to other industry standards and baselines.
---
## 2. Chart Metadata and Axes
* **Y-Axis Title:** Avg. Reference-Free Eval Scores
* **Y-Axis Range:** 72 to 86 (increments of 2).
* **X-Axis Title:** Model Size (B)
* **X-Axis Categories:**
* **13B**: Models with approximately 13 billion parameters.
* **Other Sizes**: Models with varying parameter counts (typically much larger or specialized).
* **Legend (Location: Bottom Right [x≈0.85, y≈0.1]):**
* `---` (Yellow dashed line): Gold Reference.
---
## 3. Data Series and Trends
### Region A: 13B Parameter Models (Left Column)
This group contains models specifically at the 13B scale. There is a significant performance gap between the baseline models and the ALMA models.
| Model Name | Marker Type | Color | Approx. Score |
| :--- | :--- | :--- | :--- |
| **ALMA-13B-R (Ours)** | Star | Dark Purple | **~86.4** |
| **ALMA-13B-LoRA** | Star | Dark Purple | **~84.7** |
| Bayling-13B | Circle | Light Pink | ~76.7 |
| Vicuna-13B-1.1 | Circle | Light Pink | ~74.0 |
| LLaMA-1-13B | Circle | Light Pink | ~73.6 |
| LLaMA-2-13B | Circle | Light Pink | ~72.9 |
| BigTranslate | Circle | Light Pink | ~72.3 |
**Trend Analysis:** The ALMA models (stars) represent a massive vertical leap in performance compared to other 13B models (circles). An upward-pointing arrow connects **ALMA-13B-LoRA** to **ALMA-13B-R (Ours)**, labeled with the text **"CPO Fine-tuning"**, indicating that this specific fine-tuning process accounts for the performance increase from ~84.7 to ~86.4.
### Region B: Other Sizes (Right Column)
This group contains industry benchmarks and models of various (often larger) sizes.
| Model Name | Marker Type | Color | Approx. Score |
| :--- | :--- | :--- | :--- |
| GPT-4-1106-preview | Circle | Light Purple | ~86.1 |
| WMT winners | Circle | Light Purple | ~85.6 |
| Google Translate | Circle | Light Purple | ~85.1 |
| GPT-3.5-text-davinci-003 | Circle | Light Purple | ~84.3 |
| MADLAD-10B | Circle | Light Purple | ~83.9 |
| NLLB-3.3B | Circle | Light Purple | ~82.4 |
**Trend Analysis:** The models in this category cluster between scores of 82 and 86. Notably, **ALMA-13B-R (Ours)** outperforms all listed models in this category, including GPT-4-1106-preview.
---
## 4. Key Findings and Benchmarks
* **Gold Reference:** A horizontal yellow dashed line is drawn at approximately **84.2**.
* Models above this line: ALMA-13B-R, ALMA-13B-LoRA, GPT-4-1106-preview, WMT winners, Google Translate, and GPT-3.5-text-davinci-003.
* Models below this line: MADLAD-10B, NLLB-3.3B, and all other 13B baseline models.
* **Superiority of ALMA:** The "ALMA-13B-R (Ours)" model achieves the highest score on the entire chart (~86.4), surpassing the "Gold Reference" and established high-tier models like GPT-4 and Google Translate.
* **Impact of CPO:** The transition from LoRA to "R" (via CPO Fine-tuning) provides a visible performance boost of approximately 1.7 points, moving the model from just above the Gold Reference to the top of the leaderboard.