# Technical Document Extraction: Model Performance Comparison
## Chart Description
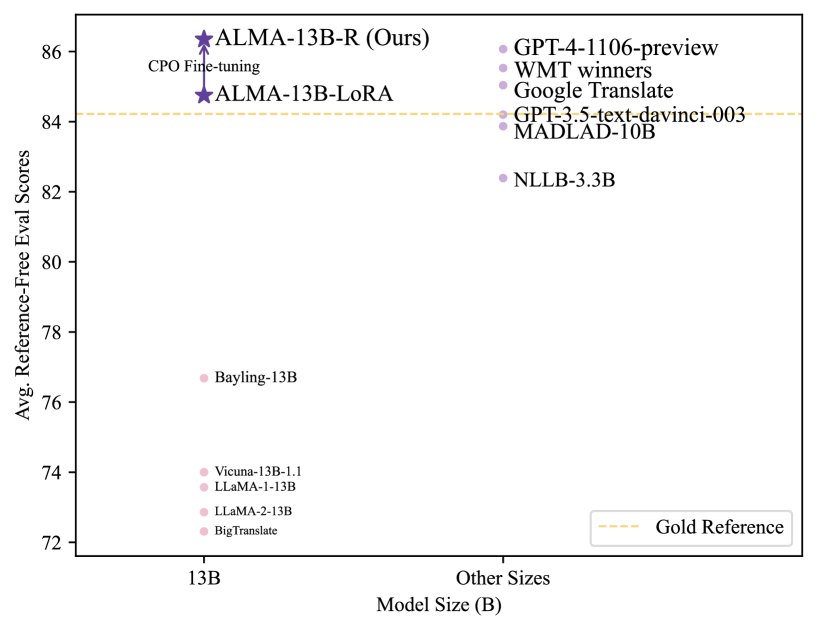
This scatter plot compares **average reference-free evaluation scores** across different **model sizes (in billions of parameters)**. The x-axis represents model size (B), while the y-axis shows evaluation scores ranging from 72 to 86. A **gold dashed line** at y=84 represents the "Gold Reference" benchmark.
---
### Key Components
1. **Axes Labels**
- **X-axis**: "Model Size (B)" (horizontal)
- **Y-axis**: "Avg. Reference-Free Eval Scores" (vertical)
2. **Legend**
- Located in the **bottom-right corner**.
- Colors correspond to specific models/sizes:
- **Purple stars**: ALMA-13B-R (Ours), ALMA-13B-LoRA
- **Pink circles**: Bayling-13B, Vicuna-13B-1.1, LLaMA-1-13B, LLaMA-2-13B, BigTranslate
- **Purple dots**: GPT-4-1106-preview, WMT winners, Google Translate, GPT-3.5-text-davinci-003, MADLAD-10B, NLLB-3.3B
3. **Data Points**
- **ALMA-13B-R (Ours)**:
- Size: 13B
- Score: 86 (highest)
- Annotated with "CPO Fine-tuning"
- **ALMA-13B-LoRA**:
- Size: 13B
- Score: 84.5
- **Bayling-13B**:
- Size: 13B
- Score: 76.5
- **Vicuna-13B-1.1**:
- Size: 13B
- Score: 74
- **LLaMA-1-13B**:
- Size: 13B
- Score: 73.5
- **LLaMA-2-13B**:
- Size: 13B
- Score: 73
- **BigTranslate**:
- Size: 13B
- Score: 72.5
- **GPT-4-1106-preview**:
- Size: 1106B
- Score: 84
- **WMT winners**:
- Size: Not specified
- Score: 84
- **Google Translate**:
- Size: Not specified
- Score: 83.5
- **GPT-3.5-text-davinci-003**:
- Size: Not specified
- Score: 83.5
- **MADLAD-10B**:
- Size: 10B
- Score: 83.5
- **NLLB-3.3B**:
- Size: 3.3B
- Score: 82
---
### Spatial Grounding
- **Legend Position**: Bottom-right corner (confirmed via visual alignment).
- **Color Consistency**:
- Purple stars match ALMA models.
- Pink circles match 13B-sized models.
- Purple dots match larger models (e.g., GPT-4, MADLAD-10B).
---
### Trend Verification
1. **ALMA Models**:
- Both ALMA-13B-R and ALMA-13B-LoRA outperform the Gold Reference (84) by significant margins.
- ALMA-13B-R (86) is the highest-performing model.
2. **13B-Size Models**:
- Scores range from 72.5 (BigTranslate) to 86 (ALMA-13B-R).
- ALMA-13B-R and ALMA-13B-LoRA dominate this category.
3. **Larger Models (10B+)**:
- GPT-4-1106-preview (1106B) and MADLAD-10B (10B) score 84 and 83.5, respectively.
- NLLB-3.3B (3.3B) scores 82, the lowest among non-13B models.
4. **Gold Reference**:
- A horizontal dashed line at y=84 serves as a benchmark. Only ALMA-13B-R exceeds it.
---
### Critical Observations
- **ALMA-13B-R** achieves the highest score (86) despite being a 13B model, outperforming larger models like GPT-4-1106-preview (1106B).
- **Fine-tuning impact**: ALMA-13B-R (CPO Fine-tuning) significantly outperforms ALMA-13B-LoRA (84.5 vs. 86).
- **Size vs. Performance**: Larger models (e.g., GPT-4) do not always correlate with higher scores, as ALMA-13B-R (13B) surpasses them.
---
### Missing Information
- No explicit numerical values for WMT winners or Google Translate beyond their scores (84 and 83.5, respectively).
- No explicit size for WMT winners or Google Translate (marked as "Not specified").
---
### Final Notes
This chart emphasizes the **performance gap** between ALMA models and other state-of-the-art systems, particularly in the 13B parameter range. The Gold Reference (84) acts as a critical benchmark, with ALMA-13B-R being the only model to exceed it.