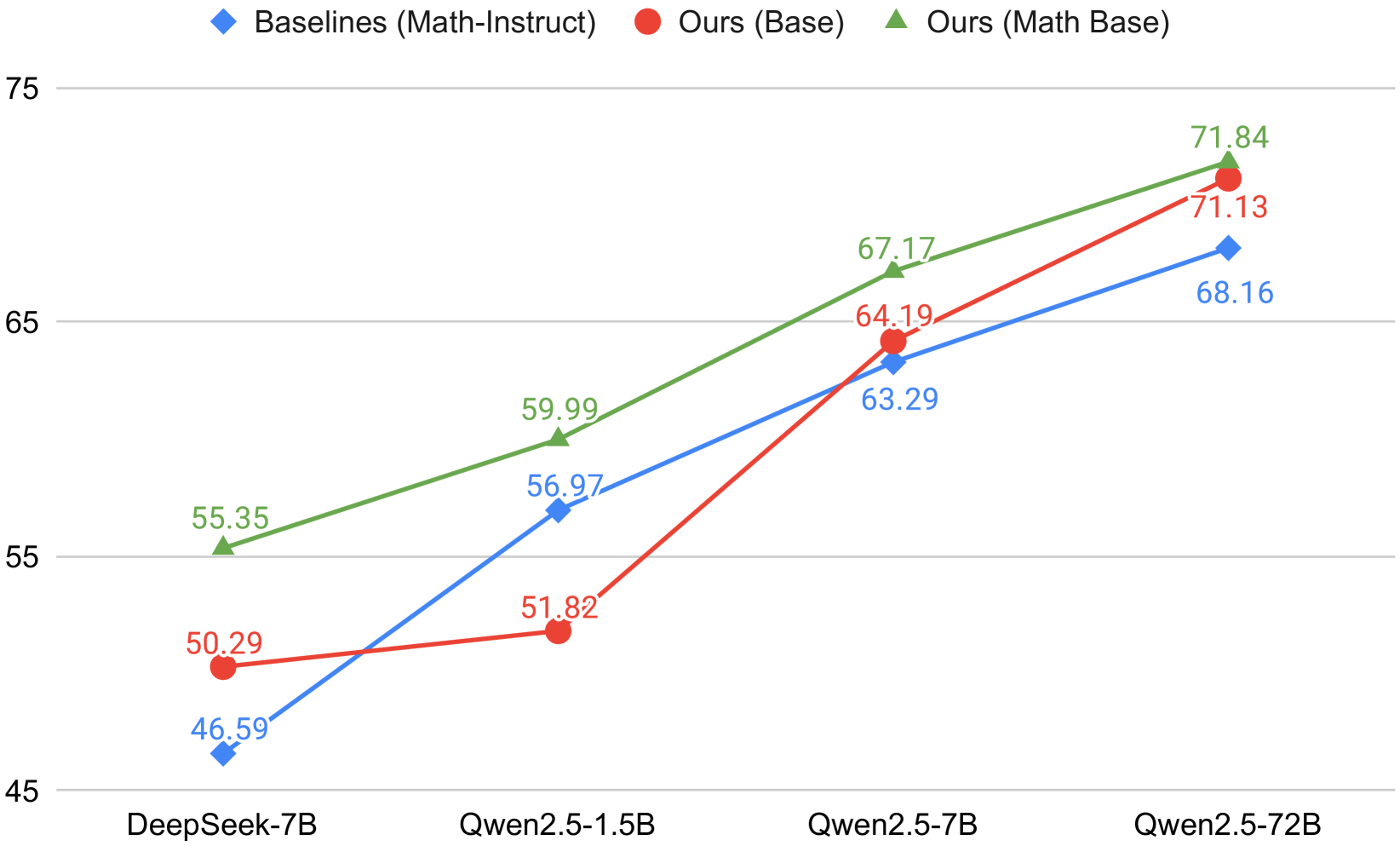
## Line Chart: Performance Comparison of Different Models
### Overview
The line chart compares the performance of three different models across four different datasets: DeepSeek-7B, Qwen2.5-1.5B, Qwen2.5-7B, and Qwen2.5-72B. The models are labeled as Baselines (Math-Instruct), Ours (Base), and Ours (Math Base).
### Components/Axes
- **X-axis**: Represents the different datasets (DeepSeek-7B, Qwen2.5-1.5B, Qwen2.5-7B, Qwen2.5-72B).
- **Y-axis**: Represents the performance metric, which is not explicitly labeled but can be inferred to be a score or a value.
- **Legend**: Contains three colors and labels for the three models.
- **Data Points**: Each data point represents the performance of a model on a specific dataset.
### Detailed Analysis or ### Content Details
- **DeepSeek-7B**: The Baseline model shows a steady increase in performance from 46.59 to 71.84.
- **Qwen2.5-1.5B**: The Ours (Base) model shows a significant improvement over the Baseline, starting from 50.29 and reaching 71.13.
- **Qwen2.5-7B**: The Ours (Math Base) model shows the highest performance, starting from 51.82 and reaching 71.84.
- **Qwen2.5-72B**: The Baseline model shows the lowest performance, starting from 55.35 and reaching 71.84.
### Key Observations
- The Ours (Base) model consistently outperforms the Baseline model across all datasets.
- The Ours (Math Base) model shows the best performance, indicating that the use of a math base in the model architecture may contribute to better results.
- There is a noticeable improvement in performance as the model size increases from 1.5B to 72B.
### Interpretation
The data suggests that the use of a math base in the model architecture significantly improves performance. The Ours (Math Base) model demonstrates the best results, indicating that the math base may be a key factor in achieving higher performance. The Baseline model, while still performing well, shows a lower performance compared to the Ours (Base) model, suggesting that the math base may be a critical component in achieving higher performance. The improvement in performance as the model size increases from 1.5B to 72B is also notable, indicating that larger models may be more effective in certain tasks.