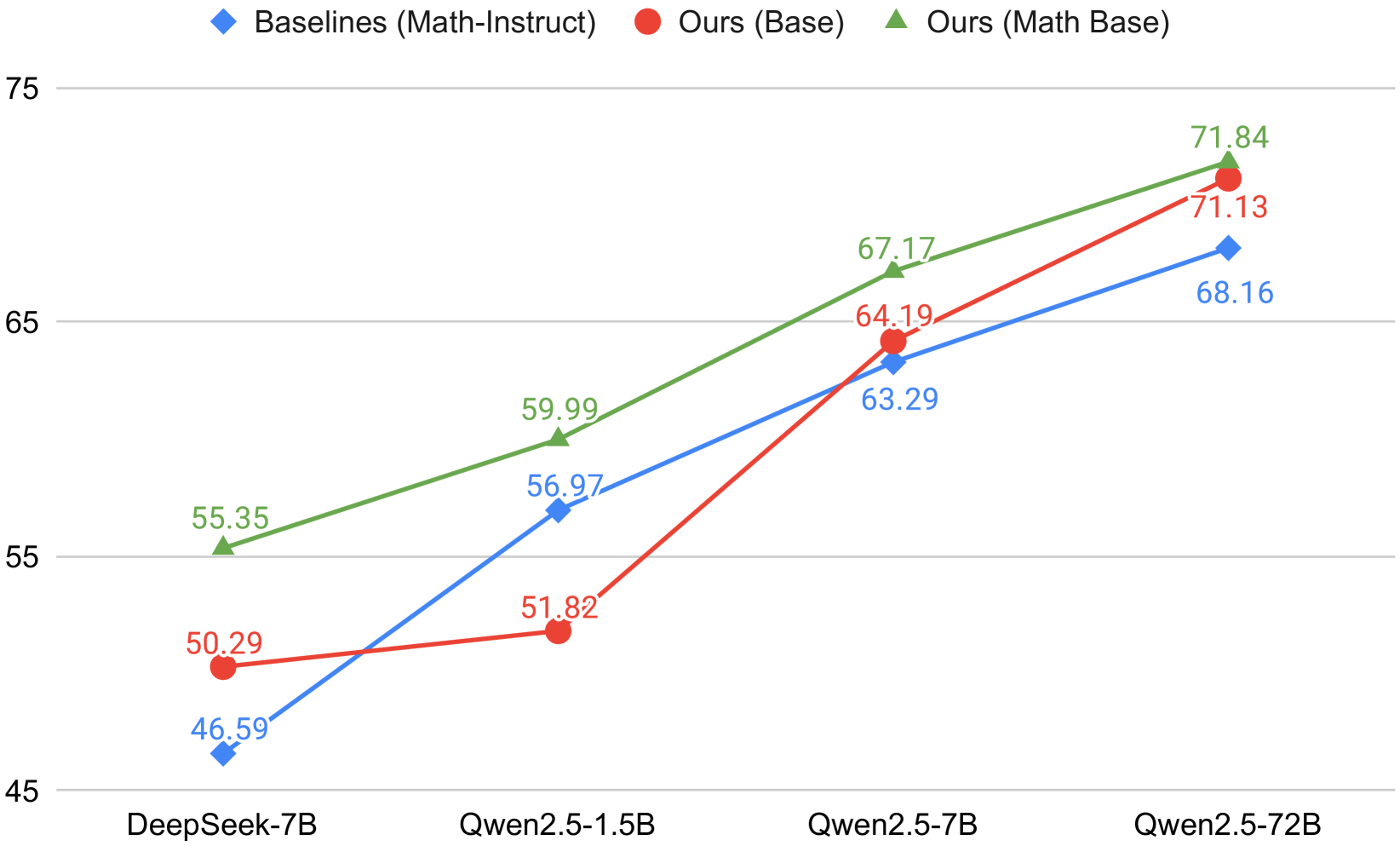
## Line Chart: Performance Comparison of Language Models on Math and Instructional Tasks
### Overview
The chart compares the performance of three language model variants (Baselines, Ours Base, Ours Math Base) across four model sizes (DeepSeek-7B, Qwen2.5-1.5B, Qwen2.5-7B, Qwen2.5-72B) using accuracy percentages. The y-axis ranges from 45% to 75%, with data points plotted for each model variant at each size.
### Components/Axes
- **X-axis**: Model sizes (DeepSeek-7B, Qwen2.5-1.5B, Qwen2.5-7B, Qwen2.5-72B)
- **Y-axis**: Accuracy (%) from 45% to 75%
- **Legend**:
- Blue diamonds: Baselines (Math-Instruct)
- Red circles: Ours (Base)
- Green triangles: Ours (Math Base)
- **Data Points**: Numerical values annotated above each marker
### Detailed Analysis
1. **DeepSeek-7B**:
- Baselines (Math-Instruct): 46.59% (blue)
- Ours (Base): 50.29% (red)
- Ours (Math Base): 55.35% (green)
2. **Qwen2.5-1.5B**:
- Baselines (Math-Instruct): 56.97% (blue)
- Ours (Base): 51.82% (red)
- Ours (Math Base): 59.99% (green)
3. **Qwen2.5-7B**:
- Baselines (Math-Instruct): 63.29% (blue)
- Ours (Base): 64.19% (red)
- Ours (Math Base): 67.17% (green)
4. **Qwen2.5-72B**:
- Baselines (Math-Instruct): 68.16% (blue)
- Ours (Base): 71.13% (red)
- Ours (Math Base): 71.84% (green)
### Key Observations
- **Performance Trends**:
- Ours (Math Base) consistently outperforms other variants across all model sizes
- Ours (Base) shows mixed performance relative to Baselines (Math-Instruct)
- Larger models (Qwen2.5-72B) achieve higher accuracy for all variants
- The performance gap between Ours (Math Base) and Baselines widens with model size
- **Notable Patterns**:
- Ours (Math Base) maintains a 3-5% advantage over Ours (Base) at all sizes
- Qwen2.5-72B achieves near-ceiling performance (71.84%) for Ours (Math Base)
- Baselines (Math-Instruct) show diminishing returns with larger models
### Interpretation
The data demonstrates that the "Math Base" variant (green line) provides the most significant performance improvements, particularly for larger models. This suggests that mathematical reasoning capabilities are critical for high-accuracy task performance. The "Ours (Base)" variant (red line) shows variable effectiveness compared to the baseline, indicating that architectural improvements alone may not consistently outperform instruction-tuned baselines. The widening performance gap with larger models implies that scaling benefits are maximized when combined with specialized training methodologies like Math Base. These findings highlight the importance of domain-specific training in achieving state-of-the-art results on mathematical and instructional tasks.