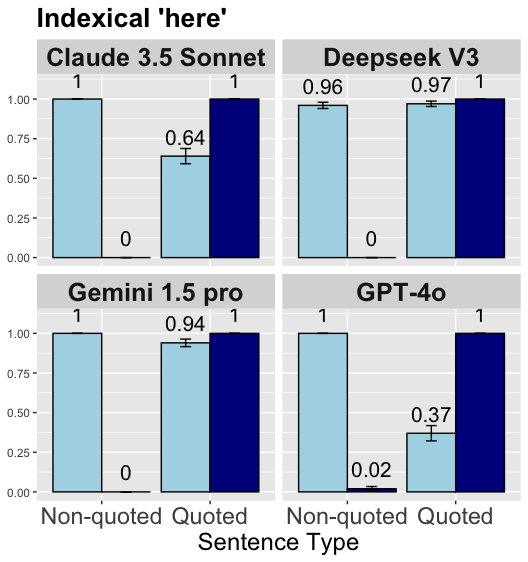
## Bar Chart: Indexical 'here'
### Overview
The image presents a bar chart comparing the performance of four language models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o) on a task involving the indexical word "here." The chart compares the models' performance on "Non-quoted" and "Quoted" sentence types. The y-axis represents a score, presumably a measure of accuracy or correctness.
### Components/Axes
* **Title:** Indexical 'here'
* **X-axis:** Sentence Type (Categories: Non-quoted, Quoted)
* **Y-axis:** Numerical scale ranging from 0.00 to 1.00, with increments of 0.25.
* **Models:** Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, GPT-4o (each model has its own subplot)
* **Bar Colors:** Light Blue (Non-quoted), Dark Blue (Quoted)
* **Error Bars:** Present on the bars, indicating variability or uncertainty.
### Detailed Analysis
**Claude 3.5 Sonnet:**
* Non-quoted: The light blue bar reaches a value of 1.00.
* Quoted: The dark blue bar reaches a value of 1.00.
* The light blue bar has a value of 0.64 with error bars.
**Deepseek V3:**
* Non-quoted: The light blue bar reaches a value of 0.96 with error bars.
* Quoted: The dark blue bar reaches a value of 1.00.
* The light blue bar has a value of 0.97 with error bars.
**Gemini 1.5 pro:**
* Non-quoted: The light blue bar reaches a value of 1.00.
* Quoted: The dark blue bar reaches a value of 1.00.
* The light blue bar has a value of 0.94 with error bars.
**GPT-4o:**
* Non-quoted: The light blue bar reaches a value of 1.00.
* Quoted: The dark blue bar reaches a value of 1.00.
* The light blue bar has a value of 0.37 with error bars.
* The light blue bar has a value of 0.02 with error bars.
### Key Observations
* All models perform well on "Quoted" sentences, achieving scores close to 1.00.
* There is more variability in performance on "Non-quoted" sentences.
* GPT-4o shows the lowest performance on "Quoted" sentences compared to other models.
### Interpretation
The chart suggests that all four language models are generally proficient at handling the indexical word "here" when it appears in quoted sentences. However, there are notable differences in their ability to handle "here" in non-quoted contexts. GPT-4o, in particular, seems to struggle with non-quoted instances, indicating a potential weakness in its understanding or processing of this specific linguistic phenomenon. The error bars provide an indication of the variability in the models' performance, which could be due to factors such as the specific wording of the sentences or the inherent stochasticity of the models.