\n
## Bar Chart: Indexical 'here' Performance
### Overview
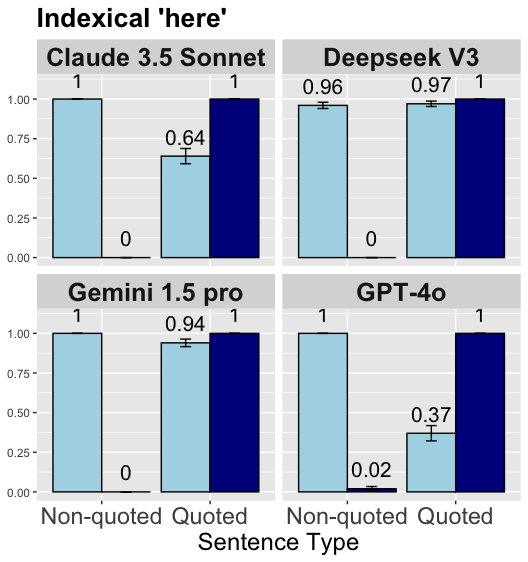
The image presents a bar chart comparing the performance of four large language models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o) on a task involving the indexical term "here". The performance is evaluated based on "Non-quoted" and "Quoted" sentence types. Each bar represents the model's score, with error bars indicating the uncertainty.
### Components/Axes
* **Title:** "Indexical 'here'"
* **X-axis:** "Sentence Type" with categories "Non-quoted" and "Quoted".
* **Y-axis:** Scale ranging from 0.00 to 1.00, representing the performance score.
* **Models:** Four models are compared: Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o. Each model has its own subplot.
* **Bars:** Light blue bars represent "Non-quoted" sentences, and dark blue bars represent "Quoted" sentences.
* **Error Bars:** Black error bars indicate the uncertainty associated with each score.
* **Values:** Numerical values are displayed above each bar, representing the performance score.
### Detailed Analysis
The chart is divided into four subplots, one for each model.
**1. Claude 3.5 Sonnet (Top-Left)**
* **Non-quoted:** The light blue bar for "Non-quoted" sentences has a value of 1.00.
* **Quoted:** The dark blue bar for "Quoted" sentences has a value of approximately 0.64, with an error bar extending from roughly 0.55 to 0.73.
* The value "0" is displayed below both bars.
**2. Deepseek V3 (Top-Right)**
* **Non-quoted:** The light blue bar for "Non-quoted" sentences has a value of 0.96, with an error bar extending from approximately 0.90 to 1.02.
* **Quoted:** The dark blue bar for "Quoted" sentences has a value of 0.97, with an error bar extending from approximately 0.91 to 1.03.
* The value "0" is displayed below both bars.
**3. Gemini 1.5 pro (Bottom-Left)**
* **Non-quoted:** The light blue bar for "Non-quoted" sentences has a value of 1.00.
* **Quoted:** The dark blue bar for "Quoted" sentences has a value of approximately 0.94, with an error bar extending from roughly 0.85 to 1.03.
* The value "0" is displayed below both bars.
**4. GPT-4o (Bottom-Right)**
* **Non-quoted:** The light blue bar for "Non-quoted" sentences has a value of 1.00.
* **Quoted:** The dark blue bar for "Quoted" sentences has a value of approximately 0.37, with an error bar extending from roughly 0.28 to 0.46. The value "0.02" is displayed below the bar.
### Key Observations
* Claude 3.5 Sonnet, Gemini 1.5 pro, and GPT-4o all perform perfectly on non-quoted sentences (score of 1.00).
* GPT-4o exhibits significantly lower performance on quoted sentences (0.37) compared to the other models.
* Deepseek V3 shows very consistent performance across both sentence types, with scores close to 1.00.
* The error bars for Deepseek V3 are relatively small, indicating high confidence in its performance.
* Claude 3.5 Sonnet and Gemini 1.5 pro show a noticeable drop in performance when dealing with quoted sentences, but still maintain relatively high scores.
### Interpretation
The data suggests that the task of understanding the indexical term "here" is generally easier for these models when presented in non-quoted sentences. The significant drop in performance for GPT-4o on quoted sentences indicates a potential weakness in its ability to correctly interpret the reference of "here" when it's part of a direct quote. This could be due to difficulties in distinguishing between the speaker/writer of the quote and the context in which the quote is being used. The consistent performance of Deepseek V3 suggests it is more robust to this type of linguistic variation. The "0" values displayed below the bars are unclear in their meaning, but may represent a baseline or a minimum threshold. The error bars provide a measure of the variability in the model's performance, allowing for a more nuanced comparison.