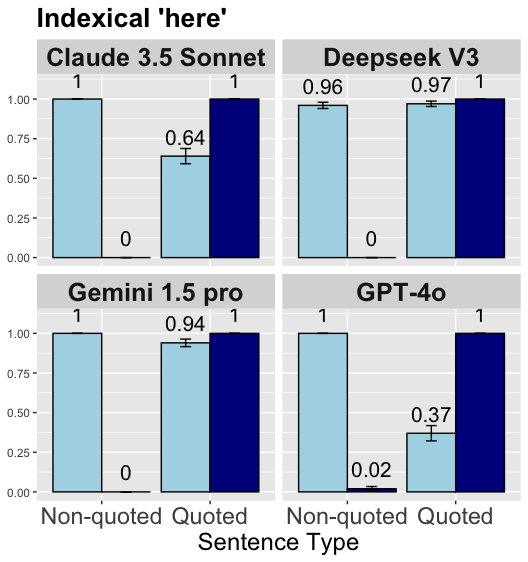
## [Bar Chart]: Indexical 'here' (AI Model Performance on Non-quoted vs. Quoted Sentences)
### Overview
The image is a bar chart with four subplots, each representing a different AI model (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, GPT-4o). The x-axis of each subplot is labeled "Sentence Type" with two categories: *Non-quoted* (light blue bars) and *Quoted* (dark blue bars). The y-axis ranges from 0.00 to 1.00 (likely a performance metric, e.g., accuracy or probability). Error bars (small vertical lines) indicate variability in performance for some bars.
### Components/Axes
- **Title:** "Indexical 'here'" (top of the chart).
- **Subplots (Models):**
- Top-Left: *Claude 3.5 Sonnet*
- Top-Right: *Deepseek V3*
- Bottom-Left: *Gemini 1.5 pro*
- Bottom-Right: *GPT-4o*
- **X-axis (per subplot):** "Sentence Type" with categories:
- *Non-quoted* (light blue bars)
- *Quoted* (dark blue bars)
- **Y-axis (per subplot):** Numerical scale (0.00, 0.25, 0.50, 0.75, 1.00).
- **Color Coding:** Light blue = *Non-quoted*; Dark blue = *Quoted* (consistent across subplots).
- **Error Bars:** Small vertical lines above bars (e.g., Claude 3.5 Sonnet’s *Quoted* bar, Deepseek V3’s bars, etc.).
### Detailed Analysis (Per Model)
#### 1. Claude 3.5 Sonnet (Top-Left)
- *Non-quoted* (light blue): Bar height = **1.00** (no visible error bar, suggesting consistent performance).
- *Quoted* (dark blue): Bar height = **0.64** (with error bar, indicating variability around this value).
#### 2. Deepseek V3 (Top-Right)
- *Non-quoted* (light blue): Bar height = **0.96** (with error bar).
- *Quoted* (dark blue): Bar height = **0.97** (with error bar, close to *Non-quoted* performance).
#### 3. Gemini 1.5 pro (Bottom-Left)
- *Non-quoted* (light blue): Bar height = **1.00** (no visible error bar).
- *Quoted* (dark blue): Bar height = **0.94** (with error bar, slight decrease from *Non-quoted*).
#### 4. GPT-4o (Bottom-Right)
- *Non-quoted* (light blue): Bar height = **1.00** (no visible error bar).
- *Quoted* (dark blue): Bar height = **0.37** (with error bar, drastic decrease from *Non-quoted*).
### Key Observations
- **Non-quoted Performance:** Most models (Claude 3.5 Sonnet, Gemini 1.5 pro, GPT-4o) achieve a perfect score (1.00) for *Non-quoted* sentences; Deepseek V3 scores 0.96 (near-perfect).
- **Quoted Performance:**
- Claude 3.5 Sonnet and GPT-4o show significant drops (0.64 and 0.37, respectively), indicating difficulty with quoted contexts.
- Deepseek V3 and Gemini 1.5 pro maintain high performance (0.97 and 0.94), suggesting robustness to quoted sentences.
- **Error Bars:** Most *Quoted* bars have error bars (indicating variability), while *Non-quoted* bars (except Deepseek V3) have no visible error bars (consistent performance).
### Interpretation
The chart compares AI models’ performance on *Non-quoted* vs. *Quoted* sentences (likely in a task like indexical reference resolution, per the title "Indexical 'here'").
- **Non-quoted Sentences:** Strong baseline performance (most models score 1.00 or near-1.00), suggesting proficiency in non-quoted contexts.
- **Quoted Sentences:** Performance varies widely:
- Claude 3.5 Sonnet and GPT-4o struggle (large drops), while Deepseek V3 and Gemini 1.5 pro remain robust.
- This suggests differences in how models handle contextual nuances (e.g., quoted speech) — possibly due to training data, architecture, or fine-tuning.
The data highlights that some models (Deepseek V3, Gemini 1.5 pro) are better equipped to handle quoted indexical references, while others (Claude 3.5 Sonnet, GPT-4o) face challenges in these contexts.