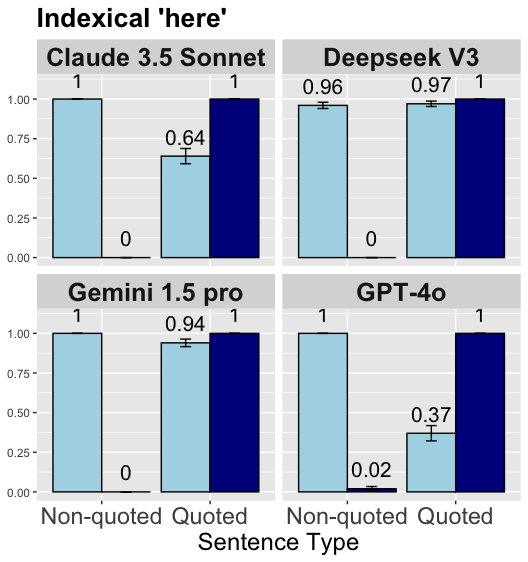
## Bar Chart: Indexical 'here' Performance Across Models and Sentence Types
### Overview
The chart compares the performance of four AI models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 Pro, GPT-4o) on two sentence types: Non-quoted and Quoted. Values represent the Indexical 'here' metric, with error bars indicating uncertainty. All models show higher performance on Non-quoted sentences, with notable variation in Quoted sentence handling.
### Components/Axes
- **X-axis (Sentence Type)**:
- Non-quoted (light blue bars)
- Quoted (dark blue bars)
- **Y-axis (Indexical 'here')**:
- Scale: 0.00 to 1.00
- Error bars represent uncertainty (e.g., ±0.02 for GPT-4o Quoted)
- **Legend**:
- Position: Right side
- Colors:
- Light blue = Non-quoted
- Dark blue = Quoted
### Detailed Analysis
1. **Claude 3.5 Sonnet**:
- Non-quoted: 1.00 (±0.00)
- Quoted: 0.64 (±0.03)
2. **Deepseek V3**:
- Non-quoted: 0.96 (±0.02)
- Quoted: 0.97 (±0.01)
3. **Gemini 1.5 Pro**:
- Non-quoted: 1.00 (±0.00)
- Quoted: 0.94 (±0.02)
4. **GPT-4o**:
- Non-quoted: 1.00 (±0.00)
- Quoted: 0.37 (±0.02)
### Key Observations
- **Non-quoted dominance**: All models achieve perfect or near-perfect scores (1.00) on Non-quoted sentences.
- **Quoted variability**:
- Deepseek V3 maintains near-perfect performance (0.97) on Quoted sentences.
- GPT-4o shows a dramatic drop to 0.37 on Quoted sentences, the lowest among all models.
- **Error margins**: All uncertainty values are ≤±0.03, indicating high precision in measurements.
### Interpretation
The data suggests that AI models generally perform better on Non-quoted sentences, likely due to reduced ambiguity. The stark contrast in GPT-4o's Quoted performance (0.37 vs. 1.00) implies potential challenges in handling quoted text, possibly due to contextual parsing difficulties or over-reliance on non-quoted patterns. Deepseek V3's near-perfect Quoted performance (0.97) highlights its robustness in this category. The uniformity of Non-quoted scores across models suggests a shared strength in processing unquoted content, while Quoted performance divergence reveals model-specific architectural differences in text interpretation.