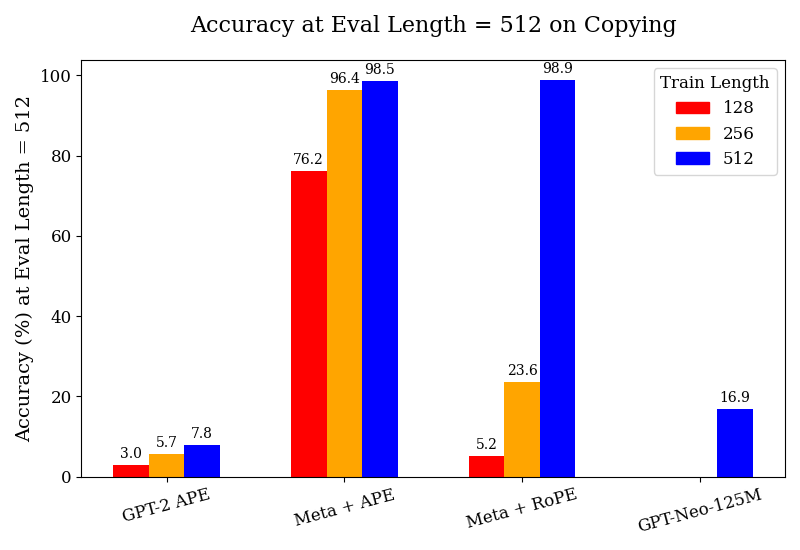
## Bar Chart: Accuracy at Eval Length = 512 on Copying
### Overview
The chart compares the accuracy of different language models (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M) at an evaluation length of 512 characters for a copying task. Accuracy is measured as a percentage, with three training lengths (128, 256, 512 tokens) represented by distinct colors (red, orange, blue). The chart emphasizes performance trends across models and training scales.
### Components/Axes
- **X-Axis (Categories)**:
- GPT-2 APE
- Meta + APE
- Meta + RoPE
- GPT-Neo-125M
- **Y-Axis (Values)**: Accuracy (%) ranging from 0 to 100.
- **Legend**:
- Red = Train Length = 128
- Orange = Train Length = 256
- Blue = Train Length = 512
- **Bar Structure**: Each model has three grouped bars (one per training length), except GPT-Neo-125M, which only has a blue bar (512).
### Detailed Analysis
1. **GPT-2 APE**:
- Train Length = 128: 3.0% (red)
- Train Length = 256: 5.7% (orange)
- Train Length = 512: 7.8% (blue)
- *Trend*: Gradual improvement with longer training, but remains the lowest-performing model.
2. **Meta + APE**:
- Train Length = 128: 76.2% (red)
- Train Length = 256: 96.4% (orange)
- Train Length = 512: 98.5% (blue)
- *Trend*: Sharp improvement from 128 to 256, then marginal gains at 512. Highest accuracy among all models at 512.
3. **Meta + RoPE**:
- Train Length = 128: 5.2% (red)
- Train Length = 256: 23.6% (orange)
- Train Length = 512: 98.9% (blue)
- *Trend*: Dramatic leap from 256 to 512 training length, achieving the highest accuracy overall.
4. **GPT-Neo-125M**:
- Train Length = 512: 16.9% (blue)
- *Trend*: Only data point for this model; significantly lower than Meta models at the same training length.
### Key Observations
- **Training Length Impact**: Longer training (512) consistently improves accuracy across all models, with the largest gains observed in Meta + RoPE (23.6% → 98.9%).
- **Model Performance**: Meta models (Meta + APE, Meta + RoPE) dominate, achieving >98% accuracy at 512 training length. GPT-2 APE and GPT-Neo-125M lag far behind.
- **Outlier**: GPT-Neo-125M’s 16.9% accuracy at 512 is anomalously low compared to other models at the same training length.
### Interpretation
The data suggests that **training length is a critical factor** in model performance for copying tasks, with diminishing returns after a certain point (e.g., Meta + APE’s 96.4% at 256 vs. 98.5% at 512). The **Meta + RoPE** configuration demonstrates the most significant scalability, likely due to architectural advantages (e.g., RoPE positional encoding). Conversely, GPT-Neo-125M’s poor performance at 512 hints at inherent limitations in its design or training data. The stark contrast between Meta and GPT models underscores the importance of architectural choices in handling long-sequence tasks.