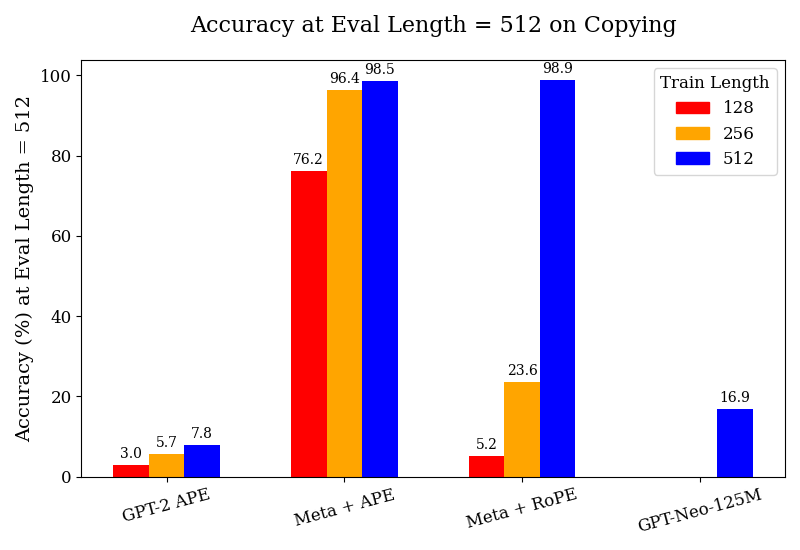
## Bar Chart: Accuracy at Eval Length = 512 on Copying
### Overview
The image is a bar chart comparing the accuracy of different language models (GPT-2 APE, Meta + APE, Meta + RoPE, and GPT-Neo-125M) on a copying task, evaluated at a length of 512. The chart shows the accuracy (%) on the y-axis and the model types on the x-axis. The bars are grouped by model type, with each group containing bars representing different training lengths (128, 256, and 512).
### Components/Axes
* **Title:** Accuracy at Eval Length = 512 on Copying
* **X-axis:** Model types: GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M
* **Y-axis:** Accuracy (%) at Eval Length = 512, with a scale from 0 to 100.
* **Legend (Top-Right):**
* Red: Train Length 128
* Orange: Train Length 256
* Blue: Train Length 512
### Detailed Analysis
The chart presents accuracy values for each model type at different training lengths.
* **GPT-2 APE:**
* Train Length 128 (Red): 3.0%
* Train Length 256 (Orange): 5.7%
* Train Length 512 (Blue): 7.8%
* Trend: Accuracy increases slightly with increasing training length.
* **Meta + APE:**
* Train Length 128 (Red): 76.2%
* Train Length 256 (Orange): 96.4%
* Train Length 512 (Blue): 98.5%
* Trend: Accuracy increases significantly with increasing training length.
* **Meta + RoPE:**
* Train Length 128 (Red): 5.2%
* Train Length 256 (Orange): 23.6%
* Train Length 512 (Blue): 98.9%
* Trend: Accuracy increases dramatically with increasing training length.
* **GPT-Neo-125M:**
* Train Length 512 (Blue): 16.9%
* Note: Only the 512 training length is shown for this model.
### Key Observations
* Meta + APE and Meta + RoPE models achieve significantly higher accuracy than GPT-2 APE and GPT-Neo-125M, especially with longer training lengths.
* For GPT-2 APE, the accuracy remains low across all training lengths.
* For Meta + APE and Meta + RoPE, the accuracy increases substantially as the training length increases from 128 to 512.
* GPT-Neo-125M has a moderate accuracy of 16.9% at a training length of 512.
### Interpretation
The data suggests that the Meta + APE and Meta + RoPE models are more effective at the copying task, particularly when trained with longer sequences. The GPT-2 APE model struggles with this task, regardless of the training length. The GPT-Neo-125M model shows a modest performance. The substantial increase in accuracy for Meta + APE and Meta + RoPE with longer training lengths indicates that these models benefit significantly from being exposed to more data during training. The difference in performance between the models likely stems from architectural differences and the effectiveness of the positional embeddings (APE vs. RoPE) used in each model. The evaluation length is fixed at 512, so the training length is the independent variable.