\n
## Bar Chart: Accuracy at Eval Length = 512 on Copying
### Overview
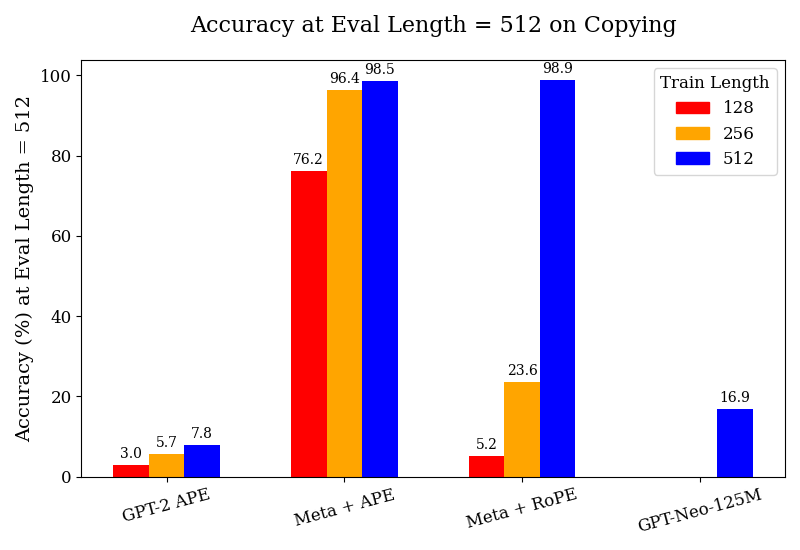
This bar chart displays the accuracy of different models (GPT-2 APE, Meta + APE, Meta + RoPE, and GPT-Neo-125M) on a copying task, evaluated at an evaluation length of 512. The accuracy is measured in percentage (%) and is shown for three different training lengths: 128, 256, and 512.
### Components/Axes
* **Title:** Accuracy at Eval Length = 512 on Copying
* **X-axis:** Model Name (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M)
* **Y-axis:** Accuracy (%) at Eval Length = 512 (Scale from 0 to 100)
* **Legend:**
* Train Length: 128 (Red)
* Train Length: 256 (Orange)
* Train Length: 512 (Blue)
### Detailed Analysis
The chart consists of four groups of three bars, one for each model and training length combination.
* **GPT-2 APE:**
* Train Length 128: Accuracy ≈ 3.0%
* Train Length 256: Accuracy ≈ 5.7%
* Train Length 512: Accuracy ≈ 7.8%
* Trend: Accuracy increases slightly with increasing training length.
* **Meta + APE:**
* Train Length 128: Accuracy ≈ 76.2%
* Train Length 256: Accuracy ≈ 96.4%
* Train Length 512: Accuracy ≈ 98.5%
* Trend: Accuracy increases significantly with increasing training length.
* **Meta + RoPE:**
* Train Length 128: Accuracy ≈ 5.2%
* Train Length 256: Accuracy ≈ 23.6%
* Train Length 512: Accuracy ≈ 98.9%
* Trend: Accuracy increases dramatically with increasing training length.
* **GPT-Neo-125M:**
* Train Length 128: Accuracy ≈ 16.9%
* Train Length 256: No bar present.
* Train Length 512: No bar present.
* Trend: Only data available for training length 128.
### Key Observations
* The "Meta + RoPE" model demonstrates the most significant improvement in accuracy as the training length increases, reaching nearly 100% accuracy with a training length of 512.
* "Meta + APE" also shows a substantial increase in accuracy with longer training lengths, but not as dramatic as "Meta + RoPE".
* "GPT-2 APE" consistently has the lowest accuracy across all training lengths.
* "GPT-Neo-125M" only has data for a training length of 128, making it difficult to compare its performance.
* The difference in accuracy between training lengths 256 and 512 is smaller for "Meta + APE" than for "Meta + RoPE".
### Interpretation
The data suggests that increasing the training length significantly improves the accuracy of these models on the copying task. The "Meta + RoPE" model appears to benefit the most from longer training lengths, potentially indicating a more effective architecture or training process for this specific task. The consistently low accuracy of "GPT-2 APE" suggests it may be less suited for this type of task or requires further optimization. The lack of data for "GPT-Neo-125M" at training lengths 256 and 512 limits the ability to draw conclusions about its performance. The large jump in accuracy for "Meta + RoPE" from training length 256 to 512 suggests a potential threshold or critical point in training length for this model. The chart highlights the importance of training length in achieving high accuracy in language models, particularly for tasks like copying.