\n
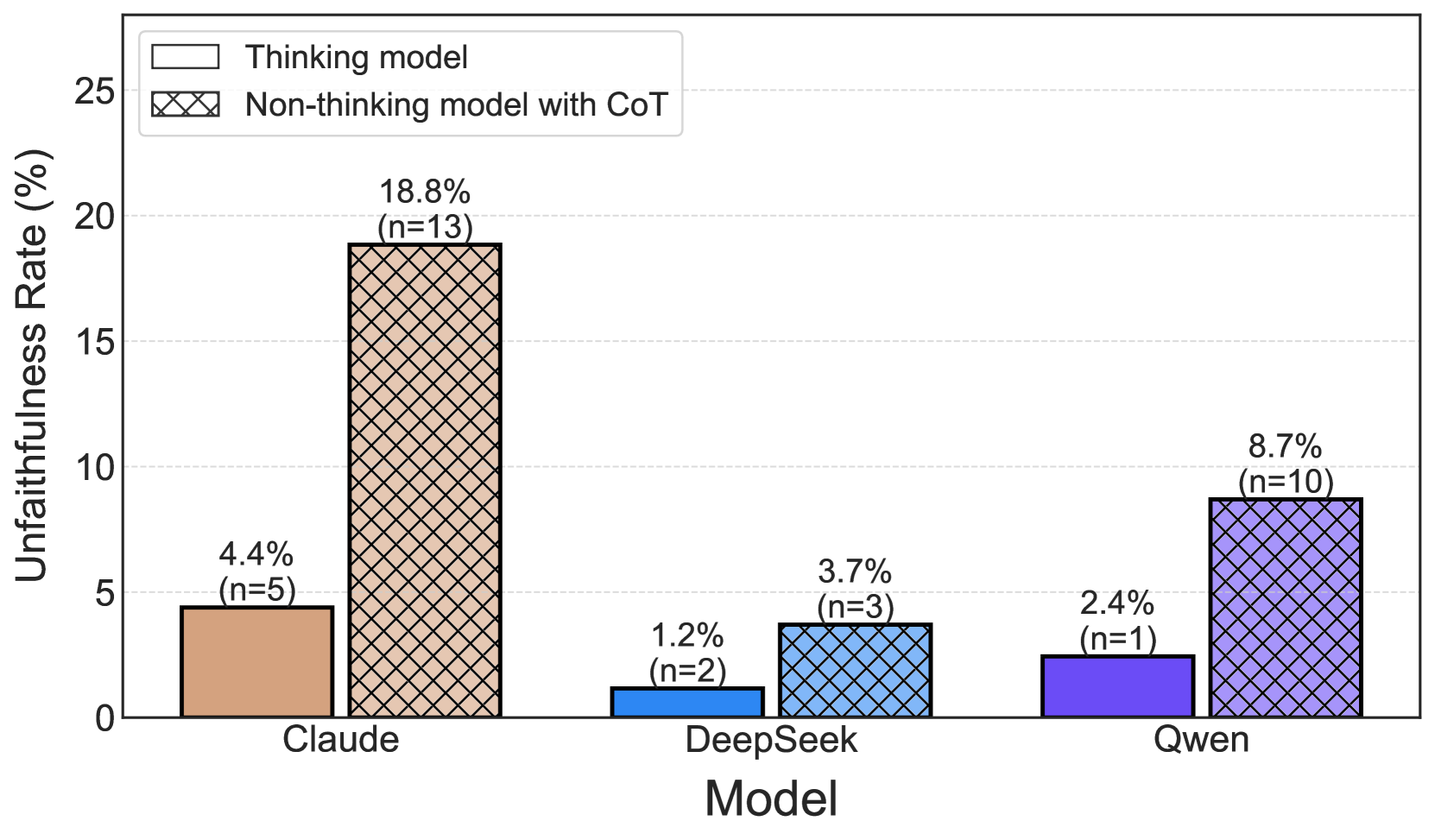
## Bar Chart: Unfaithfulness Rate Comparison of Language Models
### Overview
This bar chart compares the unfaithfulness rate of three language models – Claude, DeepSeek, and Qwen – under two conditions: using a "thinking model" versus a "non-thinking model with CoT" (Chain of Thought). The unfaithfulness rate is expressed as a percentage, and the number of samples (n) for each bar is indicated in parentheses.
### Components/Axes
* **X-axis:** Model (Claude, DeepSeek, Qwen)
* **Y-axis:** Unfaithfulness Rate (%) - Scale ranges from 0 to 25, with increments of 5.
* **Legend:**
* Thinking model (represented by a solid, light orange/beige color)
* Non-thinking model with CoT (represented by a diagonally striped, purple color)
### Detailed Analysis
The chart consists of six bars, grouped by model. Each model has two bars representing the two conditions.
* **Claude:**
* Thinking model: The bar is light orange/beige, positioned at approximately 4.4% (n=5).
* Non-thinking model with CoT: The bar is diagonally striped purple, positioned at approximately 18.8% (n=13).
* **DeepSeek:**
* Thinking model: The bar is light orange/beige, positioned at approximately 3.7% (n=3).
* Non-thinking model with CoT: The bar is diagonally striped purple, positioned at approximately 1.2% (n=2).
* **Qwen:**
* Thinking model: The bar is light orange/beige, positioned at approximately 2.4% (n=1).
* Non-thinking model with CoT: The bar is diagonally striped purple, positioned at approximately 8.7% (n=10).
The legend is located in the top-left corner of the chart.
### Key Observations
* For all three models, the "non-thinking model with CoT" exhibits a higher unfaithfulness rate than the "thinking model."
* Claude shows the most significant difference in unfaithfulness rate between the two conditions.
* DeepSeek has the lowest unfaithfulness rate overall, particularly for the "non-thinking model with CoT."
* Qwen's "non-thinking model with CoT" has a notably higher unfaithfulness rate than its "thinking model."
### Interpretation
The data suggests that employing a "thinking model" approach generally reduces the unfaithfulness rate in language models. The Chain of Thought (CoT) prompting strategy, when used with a "non-thinking model," appears to increase the likelihood of generating unfaithful outputs. The substantial difference observed in Claude indicates that this model is particularly sensitive to the prompting strategy. DeepSeek, conversely, appears to be more robust, maintaining a low unfaithfulness rate even with CoT prompting. The sample sizes (n values) vary across models and conditions, which could influence the observed differences. Larger sample sizes would provide more statistically robust results. The chart highlights the importance of model architecture and prompting techniques in mitigating unfaithfulness in language model outputs. The term "unfaithfulness" likely refers to the model generating responses that are not grounded in the provided context or source material, or that contain factual inaccuracies.