## Bar Chart: Unfaithfulness Rate Comparison Across AI Models
### Overview
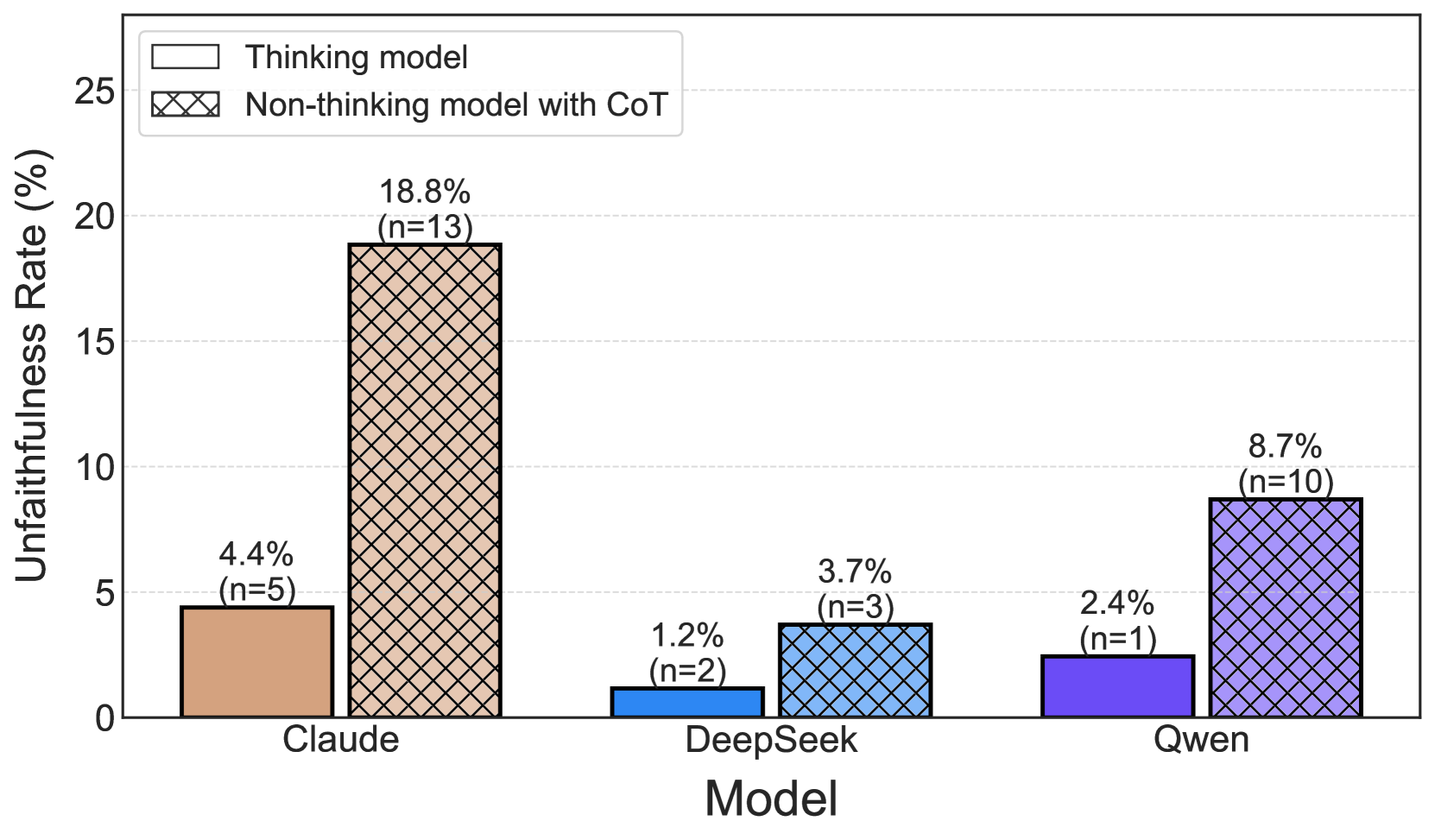
The chart compares unfaithfulness rates (%) between "Thinking models" and "Non-thinking models with Chain-of-Thought (CoT)" across three AI systems: Claude, DeepSeek, and Qwen. Data is presented as grouped bars with distinct patterns for each category.
### Components/Axes
- **X-axis**: Model names (Claude, DeepSeek, Qwen)
- **Y-axis**: Unfaithfulness Rate (%) from 0% to 25% in 5% increments
- **Legend**:
- Top-left position
- Thinking model (solid color)
- Non-thinking model with CoT (crosshatched pattern)
- **Bar Colors**:
- Claude: Brown (Thinking), Tan (Non-thinking)
- DeepSeek: Blue (Thinking), Light Blue (Non-thinking)
- Qwen: Purple (Thinking), Dark Purple (Non-thinking)
### Detailed Analysis
1. **Claude**
- Thinking model: 4.4% (n=5)
- Non-thinking model with CoT: 18.8% (n=13)
- *Visual trend*: Sharp increase from solid to crosshatched bar
2. **DeepSeek**
- Thinking model: 1.2% (n=2)
- Non-thinking model with CoT: 3.7% (n=3)
- *Visual trend*: Moderate increase with smaller absolute difference
3. **Qwen**
- Thinking model: 2.4% (n=1)
- Non-thinking model with CoT: 8.7% (n=10)
- *Visual trend*: Significant jump with largest sample size for Non-thinking
### Key Observations
- All models show higher unfaithfulness rates in Non-thinking models with CoT
- Claude exhibits the largest disparity (14.4% difference)
- DeepSeek has the smallest absolute difference (2.5%)
- Qwen demonstrates the highest absolute unfaithfulness rate overall (8.7%)
- Sample sizes vary significantly (n=1 to n=13)
### Interpretation
The data suggests CoT implementation correlates with increased unfaithfulness rates across all models, with Claude showing the most pronounced effect. This could indicate that CoT's complex reasoning pathways introduce more opportunities for error. The small sample size for Qwen's Thinking model (n=1) raises questions about statistical reliability. The consistent pattern across models implies CoT's impact on unfaithfulness is system-agnostic, though magnitude varies. The data might reflect trade-offs between reasoning depth and accuracy in AI systems.