## Bar Charts: GPT-3 vs. Human Generative Accuracy
### Overview
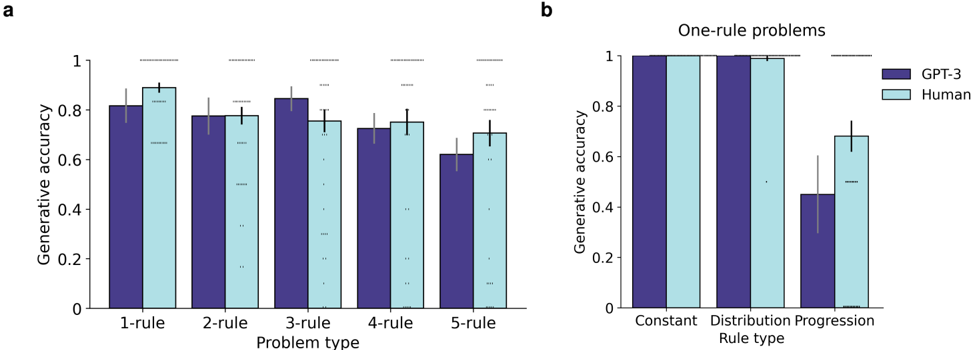
The image contains two bar charts comparing the generative accuracy of GPT-3 and humans on different types of rule-based problems. Chart (a) shows accuracy across problem types with varying numbers of rules (1-rule to 5-rule), while chart (b) focuses on one-rule problems, comparing performance on "Constant" and "Distribution Progression" rule types.
### Components/Axes
**Chart a:**
* **Title:** Implicit, but represents generative accuracy across different problem types.
* **Y-axis:** "Generative accuracy", ranging from 0 to 1.
* **X-axis:** "Problem type", with categories: "1-rule", "2-rule", "3-rule", "4-rule", "5-rule".
* **Legend:** Located in the top-right of chart b, applies to both charts.
* Dark Blue: "GPT-3"
* Light Blue: "Human"
* Error bars are present on each bar, indicating variability.
**Chart b:**
* **Title:** "One-rule problems"
* **Y-axis:** "Generative accuracy", ranging from 0 to 1.
* **X-axis:** "Rule type", with categories: "Constant", "Distribution Progression".
* **Legend:** Located in the top-right.
* Dark Blue: "GPT-3"
* Light Blue: "Human"
* Error bars are present on each bar, indicating variability.
### Detailed Analysis
**Chart a: Generative Accuracy vs. Problem Type**
* **GPT-3 (Dark Blue):**
* 1-rule: Accuracy is approximately 0.82, with an error bar extending to approximately 0.88.
* 2-rule: Accuracy is approximately 0.78, with an error bar extending to approximately 0.84.
* 3-rule: Accuracy is approximately 0.84, with an error bar extending to approximately 0.90.
* 4-rule: Accuracy is approximately 0.74, with an error bar extending to approximately 0.78.
* 5-rule: Accuracy is approximately 0.62, with an error bar extending to approximately 0.68.
* Trend: GPT-3's accuracy fluctuates, peaking at 3-rule problems and decreasing for 4-rule and 5-rule problems.
* **Human (Light Blue):**
* 1-rule: Accuracy is approximately 0.88, with an error bar extending to approximately 0.94.
* 2-rule: Accuracy is approximately 0.78, with an error bar extending to approximately 0.84.
* 3-rule: Accuracy is approximately 0.74, with an error bar extending to approximately 0.78.
* 4-rule: Accuracy is approximately 0.74, with an error bar extending to approximately 0.80.
* 5-rule: Accuracy is approximately 0.72, with an error bar extending to approximately 0.78.
* Trend: Human accuracy is relatively stable across problem types, with a slight decrease as the number of rules increases.
**Chart b: Generative Accuracy for One-Rule Problems**
* **GPT-3 (Dark Blue):**
* Constant: Accuracy is approximately 1.0, with a very small error bar.
* Distribution Progression: Accuracy is approximately 0.44, with an error bar extending to approximately 0.58.
* Trend: GPT-3 performs perfectly on constant one-rule problems but significantly worse on distribution progression problems.
* **Human (Light Blue):**
* Constant: Accuracy is approximately 1.0, with a very small error bar.
* Distribution Progression: Accuracy is approximately 0.70, with an error bar extending to approximately 0.76.
* Trend: Humans also perform perfectly on constant one-rule problems, but their accuracy is higher than GPT-3's on distribution progression problems.
### Key Observations
* In chart a, GPT-3's performance varies more across different problem types compared to human performance.
* In chart b, both GPT-3 and humans achieve perfect accuracy on "Constant" one-rule problems.
* GPT-3's accuracy drops significantly on "Distribution Progression" one-rule problems compared to humans.
* Error bars indicate the variability in the data, with some bars having larger error ranges than others.
### Interpretation
The data suggests that GPT-3's generative accuracy is highly dependent on the type of rule-based problem. While it can perform comparably to humans on some problems (e.g., 3-rule problems in chart a), it struggles with "Distribution Progression" one-rule problems (chart b). This indicates that GPT-3 may have difficulty generalizing to certain types of rules or patterns. Humans, on the other hand, show more consistent performance across different problem types, suggesting a greater ability to adapt to varying levels of complexity and rule structures. The perfect accuracy on "Constant" one-rule problems for both GPT-3 and humans indicates that these problems are relatively simple and easily solvable by both. The significant difference in performance on "Distribution Progression" problems highlights a potential weakness in GPT-3's ability to handle more complex or abstract rule-based tasks.