## Bar Charts: Generative Accuracy Comparison (GPT-3 vs. Human)
### Overview
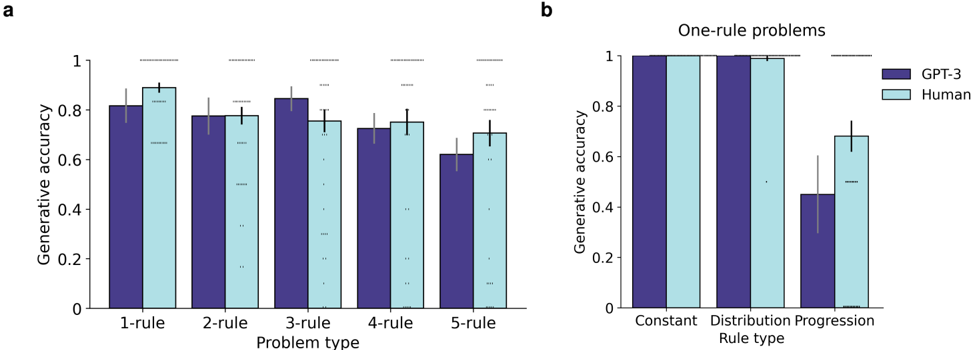
The image contains two bar charts, labeled **a** and **b**, comparing the "Generative accuracy" of GPT-3 (dark blue bars) and Human performance (light blue bars) across different problem types. Both charts share the same y-axis scale (0 to 1) and legend. The data includes error bars, indicating variability or confidence intervals.
### Components/Axes
**Common Elements:**
* **Y-axis (Both Charts):** Label: "Generative accuracy". Scale: 0 to 1, with major ticks at 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Legend (Top-Right of each chart):**
* Dark Blue Square: "GPT-3"
* Light Blue Square: "Human"
**Chart a (Left):**
* **Title/Label:** "a" (top-left corner).
* **X-axis Label:** "Problem type".
* **X-axis Categories (from left to right):** "1-rule", "2-rule", "3-rule", "4-rule", "5-rule".
* **Data Series:** For each category, two bars are shown side-by-side: GPT-3 (left, dark blue) and Human (right, light blue).
**Chart b (Right):**
* **Title/Label:** "b" (top-left corner).
* **Chart Subtitle:** "One-rule problems" (centered above the chart).
* **X-axis Label:** "Rule type".
* **X-axis Categories (from left to right):** "Constant", "Distribution", "Progression".
* **Data Series:** For each category, two bars are shown side-by-side: GPT-3 (left, dark blue) and Human (right, light blue).
### Detailed Analysis
**Chart a: Accuracy by Number of Rules**
* **Trend Verification:** Both series show a general downward trend as the number of rules increases. GPT-3's decline appears steeper than the Human's.
* **Data Points (Approximate values with estimated error bar ranges):**
* **1-rule:** GPT-3 ≈ 0.82 (error: ~0.78-0.86); Human ≈ 0.89 (error: ~0.85-0.93).
* **2-rule:** GPT-3 ≈ 0.78 (error: ~0.74-0.82); Human ≈ 0.78 (error: ~0.74-0.82).
* **3-rule:** GPT-3 ≈ 0.85 (error: ~0.81-0.89); Human ≈ 0.76 (error: ~0.72-0.80).
* **4-rule:** GPT-3 ≈ 0.73 (error: ~0.69-0.77); Human ≈ 0.76 (error: ~0.72-0.80).
* **5-rule:** GPT-3 ≈ 0.62 (error: ~0.58-0.66); Human ≈ 0.71 (error: ~0.67-0.75).
**Chart b: Accuracy for One-Rule Problems by Rule Type**
* **Trend Verification:** Performance is high and similar for "Constant" and "Distribution" rule types. A significant drop occurs for the "Progression" rule type, especially for GPT-3.
* **Data Points (Approximate values with estimated error bar ranges):**
* **Constant:** GPT-3 ≈ 1.00 (error: ~0.98-1.00); Human ≈ 1.00 (error: ~0.98-1.00).
* **Distribution:** GPT-3 ≈ 1.00 (error: ~0.98-1.00); Human ≈ 0.99 (error: ~0.95-1.00).
* **Progression:** GPT-3 ≈ 0.45 (error: ~0.30-0.60); Human ≈ 0.68 (error: ~0.60-0.76).
### Key Observations
1. **Complexity Impact (Chart a):** Generative accuracy for both GPT-3 and Humans generally decreases as the problem complexity (number of rules) increases from 1 to 5.
2. **AI vs. Human Gap (Chart a):** GPT-3 outperforms Humans on the simplest (1-rule) and most complex (3-rule, 4-rule) problems in this set, but matches or is slightly below on 2-rule and 5-rule problems. The largest performance gap favoring GPT-3 is at 3-rule problems.
3. **Rule Type Specificity (Chart b):** For single-rule problems, both GPT-3 and Humans achieve near-perfect accuracy on "Constant" and "Distribution" rules. However, a major performance divergence occurs on "Progression" rules, where GPT-3's accuracy drops to approximately 0.45, while Human accuracy remains relatively high at ~0.68.
4. **Variability:** Error bars are generally wider for GPT-3 in Chart b's "Progression" category and for both series in Chart a's higher-rule categories, suggesting less consistent performance on more difficult tasks.
### Interpretation
The data suggests that the difficulty of a generative task is not solely a function of the number of rules. The *type* of rule is a critical factor. While both AI and humans handle static ("Constant") or statistical ("Distribution") rules with high accuracy, tasks involving sequential or evolving patterns ("Progression") present a specific challenge, particularly for the AI model tested.
The trends indicate that GPT-3's performance is more sensitive to the specific cognitive demands of a rule type than to a simple count of rules. Its relative strength on 3-rule and 4-rule problems in Chart a, contrasted with its weakness on "Progression" rules in Chart b, implies that the 3- and 4-rule problems may not heavily rely on progression-type logic. This analysis highlights the importance of deconstructing problem complexity into qualitative components (rule type) rather than relying solely on quantitative measures (rule count) when evaluating and comparing AI and human reasoning capabilities.