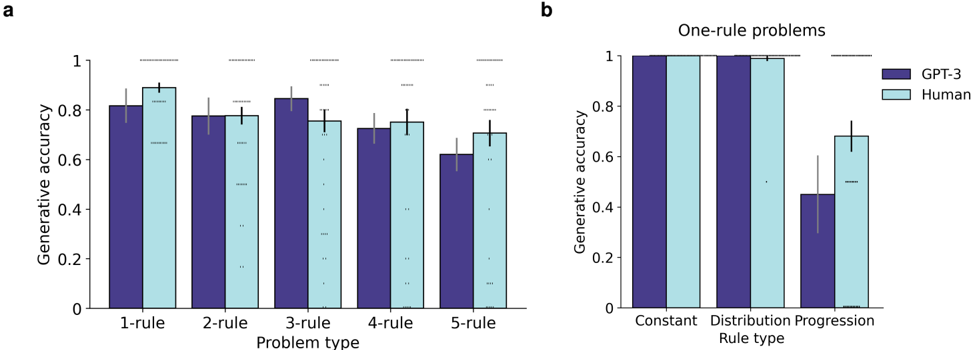
## Bar Charts: Generative Accuracy Comparison (GPT-3 vs. Humans)
### Overview
The image contains two bar charts comparing generative accuracy between GPT-3 and humans across different problem types and rule types. Chart **a** evaluates performance on multi-rule problems (1-rule to 5-rule), while chart **b** focuses on one-rule problems categorized by rule type (Constant, Distribution, Progression).
### Components/Axes
#### Chart a: Multi-Rule Problems
- **X-axis**: Problem type (1-rule, 2-rule, 3-rule, 4-rule, 5-rule).
- **Y-axis**: Generative accuracy (0 to 1.0).
- **Legend**:
- Purple bars: GPT-3.
- Light blue bars: Human.
- **Error bars**: Present for all data points, indicating variability.
#### Chart b: One-Rule Problems
- **X-axis**: Rule type (Constant, Distribution, Progression).
- **Y-axis**: Generative accuracy (0 to 1.0).
- **Legend**: Same as chart a (GPT-3: purple, Human: light blue).
### Detailed Analysis
#### Chart a: Multi-Rule Problems
- **1-rule**:
- GPT-3: ~0.82 (±0.03).
- Human: ~0.88 (±0.04).
- **2-rule**:
- GPT-3: ~0.78 (±0.05).
- Human: ~0.76 (±0.03).
- **3-rule**:
- GPT-3: ~0.84 (±0.04).
- Human: ~0.74 (±0.05).
- **4-rule**:
- GPT-3: ~0.72 (±0.06).
- Human: ~0.76 (±0.04).
- **5-rule**:
- GPT-3: ~0.63 (±0.07).
- Human: ~0.72 (±0.05).
#### Chart b: One-Rule Problems
- **Constant**:
- GPT-3: ~0.98 (±0.01).
- Human: ~0.97 (±0.02).
- **Distribution**:
- GPT-3: ~0.97 (±0.02).
- Human: ~0.96 (±0.03).
- **Progression**:
- GPT-3: ~0.45 (±0.08).
- Human: ~0.70 (±0.06).
### Key Observations
1. **Rule Complexity Impact**:
- GPT-3 outperforms humans in 1-rule and 2-rule problems but underperforms in 3-rule and higher.
- Humans maintain consistent performance across all rule types, with a notable advantage in 5-rule problems.
2. **Rule Type Specificity**:
- GPT-3 excels in Constant and Distribution rule types (~0.97–0.98 accuracy) but struggles severely in Progression rules (~0.45 accuracy).
- Humans perform comparably across all rule types, with a ~0.70 accuracy in Progression rules.
3. **Error Variability**:
- GPT-3 shows higher error margins in higher-rule problems (e.g., 5-rule: ±0.07).
- Humans exhibit relatively stable error margins (~±0.03–0.06).
### Interpretation
The data suggests that **rule complexity** significantly impacts generative accuracy, with GPT-3’s performance degrading as the number of rules increases. This aligns with the hypothesis that GPT-3 struggles with multi-step reasoning or dynamic rule interactions (e.g., Progression rules). Humans, however, demonstrate robustness across rule types, indicating superior adaptability in handling complex, multi-rule scenarios.
The stark drop in GPT-3’s accuracy for Progression rules (~0.45 vs. human ~0.70) highlights a critical limitation in its ability to model sequential or evolving constraints. This could reflect challenges in temporal reasoning or contextual dependency management, areas where human cognition typically excels.
### Spatial Grounding & Trend Verification
- **Legend Placement**: Right-aligned in both charts, ensuring clear association with bar colors.
- **Trend Consistency**:
- Chart a: GPT-3’s accuracy peaks at 3-rule (~0.84) but declines sharply thereafter, while humans plateau at ~0.72–0.88.
- Chart b: GPT-3’s Progression rule accuracy is ~50% lower than humans, confirming a significant outlier.
### Content Details
- **Error Bars**: Visually represented as vertical lines atop bars, with approximate lengths matching the ±values listed.
- **Bar Heights**: Proportional to accuracy values, with GPT-3’s Progression rule bar in chart b being notably shorter than others.
### Final Notes
The charts emphasize the need for improved modeling of multi-rule interactions in AI systems. While GPT-3 performs well in constrained, static environments (Constant/Distribution rules), its limitations in dynamic, multi-step problems (Progression rules) underscore gaps in current generative AI architectures.